Chap 3: Capital Share Bikeshare Predictor
Follow the book’s approach
notebook links:
data preprocessing, object & function definitions, train & test.
Try to train on unnormalized target data
In the previous practice in this chaper to make a failed predictor, I found that using unnormalized y data lead to better fitting result. Therefore, I want to try using unnormalized y data on the share-bike predictor here.
The notebooks here follows the the notebooks of “follow the book’s approach”.
data preprocessing & train/test part1, train/test part2 & analysis on the model.
The main result is that the predictions generated by the model became discrete, and I found that only a few neurons of the hidden layer can be active and others are mostly idle.
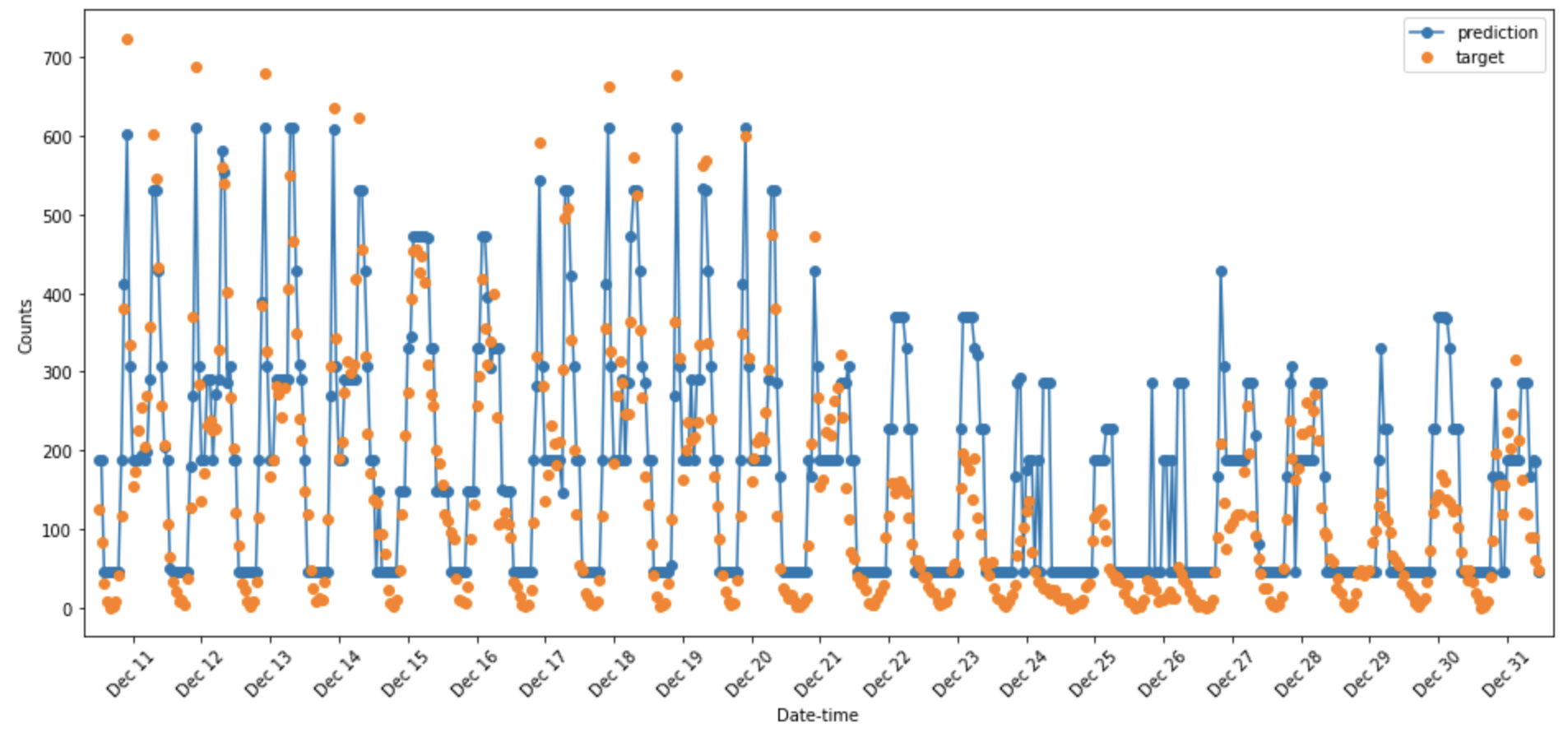
The training should be stuck by gradient vanishing for most of the neurons are stuck in the off state. My guess of the cause: By the unnormalized target values, the total loss and gradient are huge in the begining of the training, and some of the neurons quickly adapt to fit the data. After that, other neurons are in deep off-state, so they can only get far smaller gradients than the active neurons, so the training never let them adapt to improve the fitting. Change to ReLU should fix such problem by such guess.
Using ReLU indeed solve the discreteness problem. When using ReLU, using unnormalized data should have no significant unwanted effects. The notebook here also follows the notebooks of “follow the book’s approach”.
A more practical predictor: Use the 6-hour-ago data to perform prediction
As a practical application, using the data at the current moment to make predictions is unreal. We should use the data in the past to make presictions for now.