Notes for Prof. Hung-Yi Lee's ML Lecture: Transformer
Overview
For sequence-to-sequence (seq2seq) tasks, the machine has to take a variable length sequence as input and generate an output sequence whose length is determined by the machine. Transformer performs such task.
A transformer is composed of an encoder and a decoder. The encoder produces a sequence of vectors whose length is the same as the input sequence. The decoder produces the output sequence from the encoded sdquence.
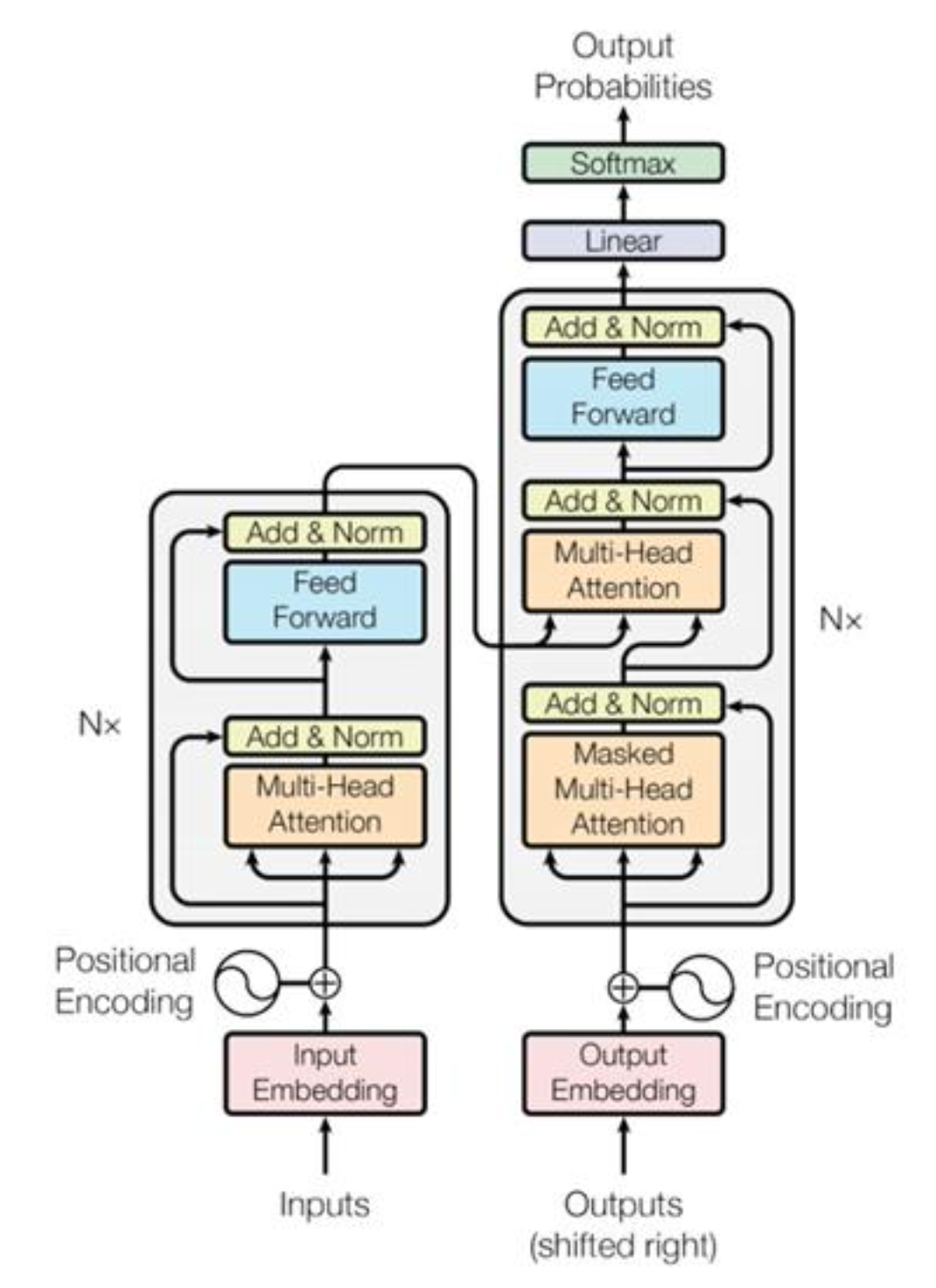
Encoder
The procedure of an encoder layer:
- Perform multi-head self-attention on the input sequence.
- Residual connection: add the input sequence to the sequence generated in (1).
- Perform layer normalization.
- Feed to a feedforward network.
- Residual connection: add the sequence from (3) to the sequence from (4).
The overall encoder is the composition of multiple encoder layers.
The layer normalization is to normalize all the features over an example.
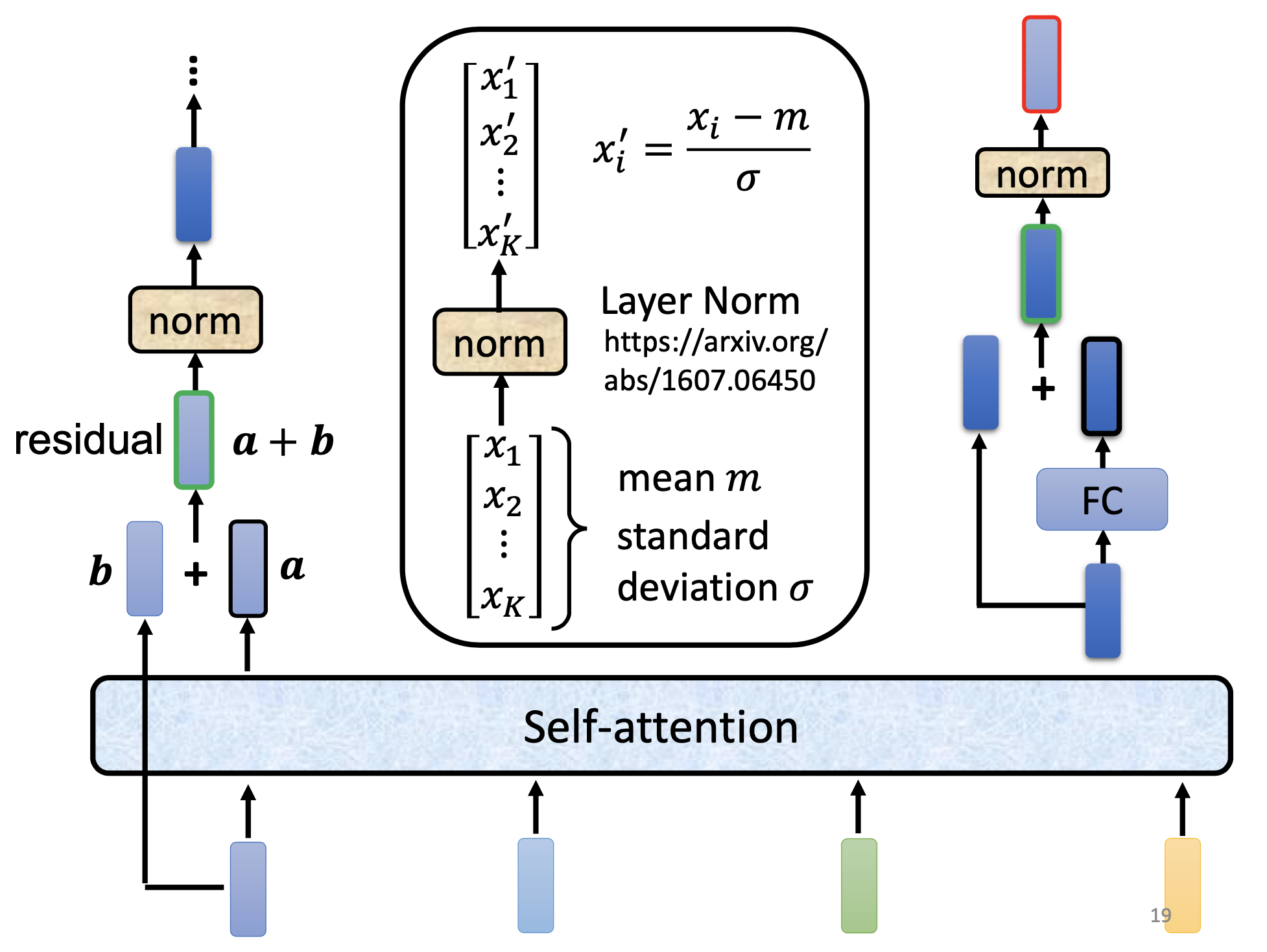
On Normalization
There are more approaches for the normalization: On Layer Normalization in the Transformer Architecture; PowerNorm: Rethinking Batch Normalization in Transformers.
Decoder
The operations of the decoder are similar to the encoder, except that the decoder use masked multi-head attention in the 1st attention module and multi-henad cross attention in the 2nd attention module.
Autoregressive (AT) & Non-Autoregressive (NAT)
The original transformer is autoregressive. The autoregressive decoder works by the following procedures:
- Feed the “start” token into the decoder, and the decoder produce the 1st output token.
- Feed the token produced by the previous step into the decoder, and the decoder produce the next token.
- Repeat (2) until the decoder produce the “stop” token.
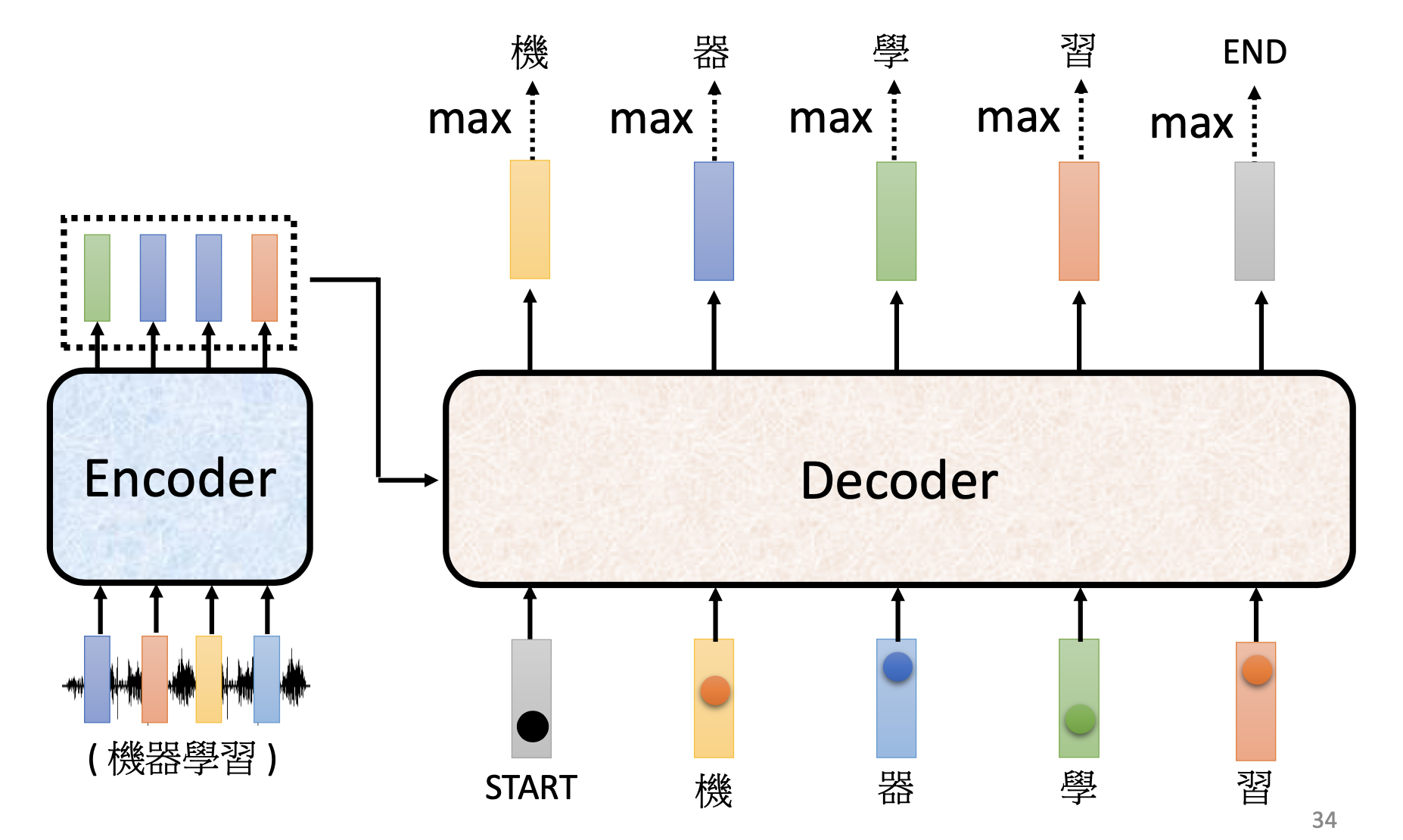
For a non-autoregressive decoder, all the tokens of the output sequence are produced simultaneously. To decide the output length, we can either train another predictor to predict the output length or let the decoder output a very long sequence and ignore tokens after “end”. The NAT decoders have some advantages. By the NAT decoders, all the outputs tokens are computed parallelly. The generation by NAT decoders is more stable in some tasks, e.g. text-to-speech (TTS). However, usually the performance of AT decoders are better than the NAT decoders. Multi-modality may be a cause. (To learn more.)
Masked Self-Attention
Consider a case that the decoder produces a sequence of length N in the end. When generating the ith token, the masked self-attention layer only sees i inputs because the i+1 to Nth tokens are not yet fed to it. As a result, we call it “masked” self-attention.
Cross-Attention
For cross attention, the query is from the decoder’s cross-attention module, and we evaluate the attention scores of the output vectors of the encoder to the query, and then calculate a final value vector from the attention scores and the value vectorsfrom the output vectors of the encoder.
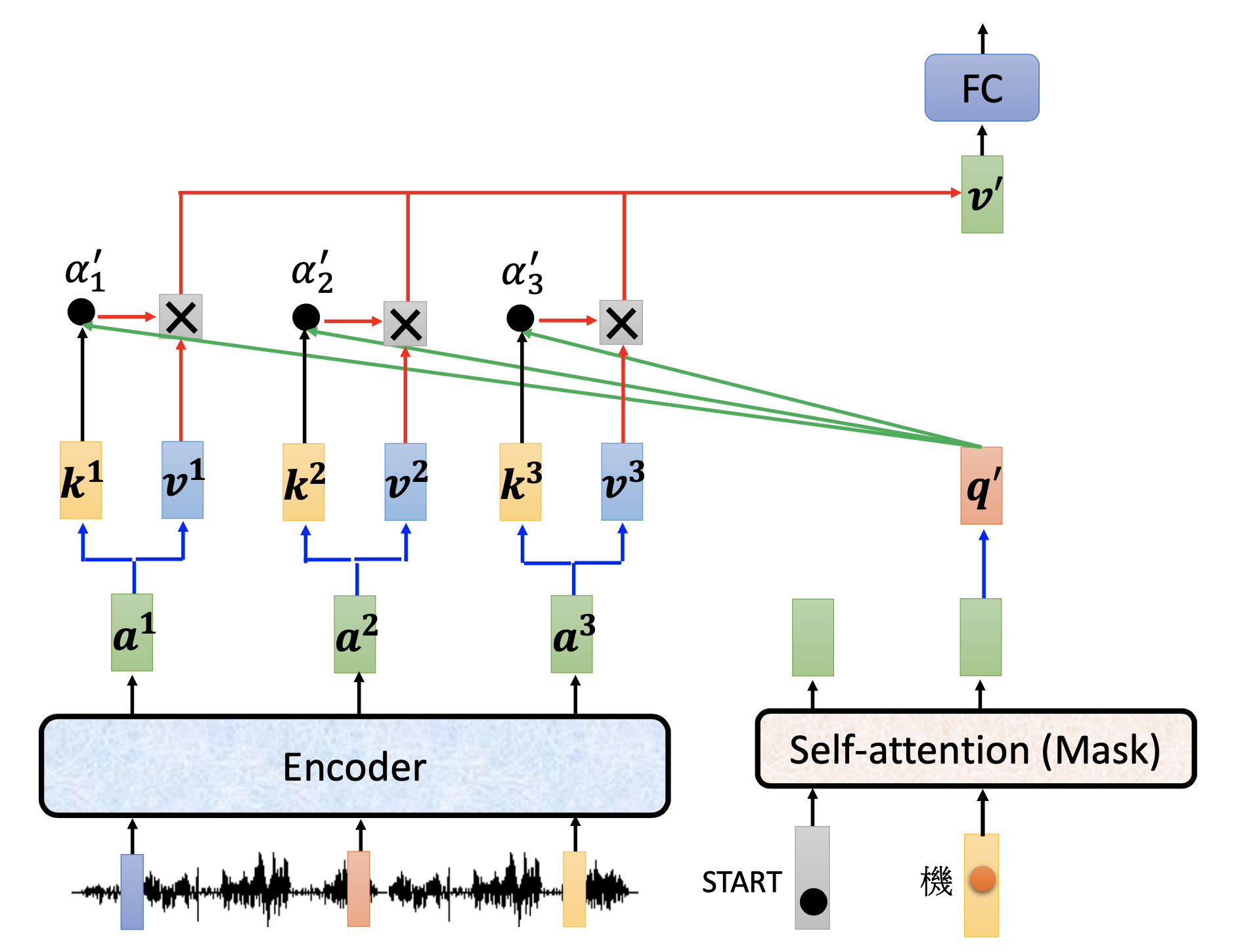
Since the encoder has multiple layers, the cross-attention is not limited to the output of the last layer of the encoder. There are further variations.
Training
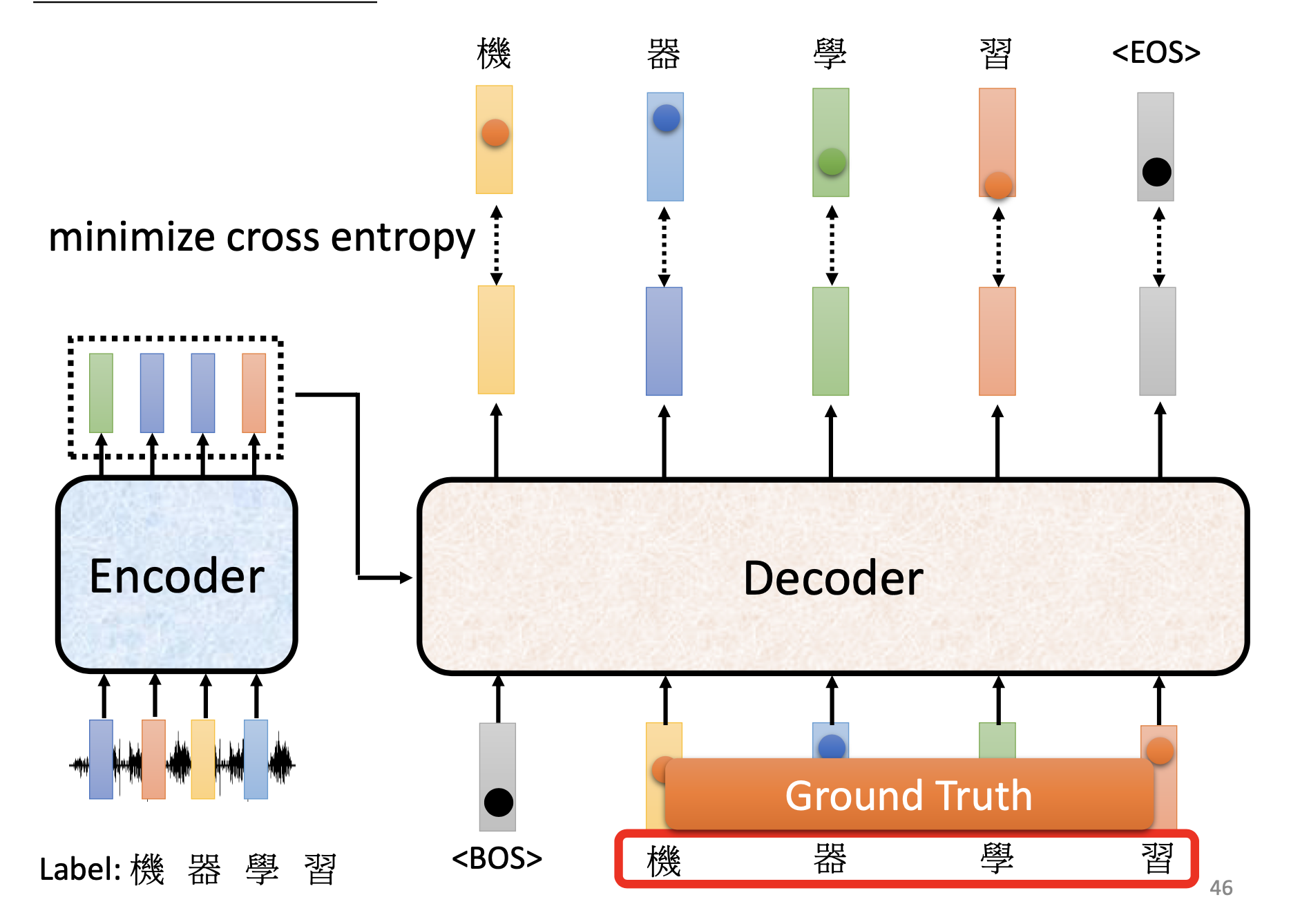
Teacher Forcing
Since the original transformer is autoregressive, when producing an output token, we feed a token into the decoder. In training, although the decoder may produce a wrong token in the previous step, we still feed the correct token into the decoder at the next step. This is teacher forcing.
Scheduled Sampling
By teacher forcing, we feed the decoder the correct tokens. However, when enferencing, the decoder may produce incorrect tokens, then the decoder will see incorrect inputs. Such mismatch is exposure bias. To deal with exposure bias, we can sometimes feed the decoder with incorrect tokens. This is scheduled sampling. Original Scheduled Sampling, Scheduled Sampling for Transformer, Parallel Scheduled Sampling.
Evaluating Metrices
When training a tranformer, we minimize the cross-entropy between the tokens generated by the decoder and the answer. However, for machine-translation, we actually evaluate the performance of the models by BLEU score. Because we cannot compute the gradients over the BLEU score, to using it as the objective function, we have to use reinforcement learning to train the models. ref
Further Discussions
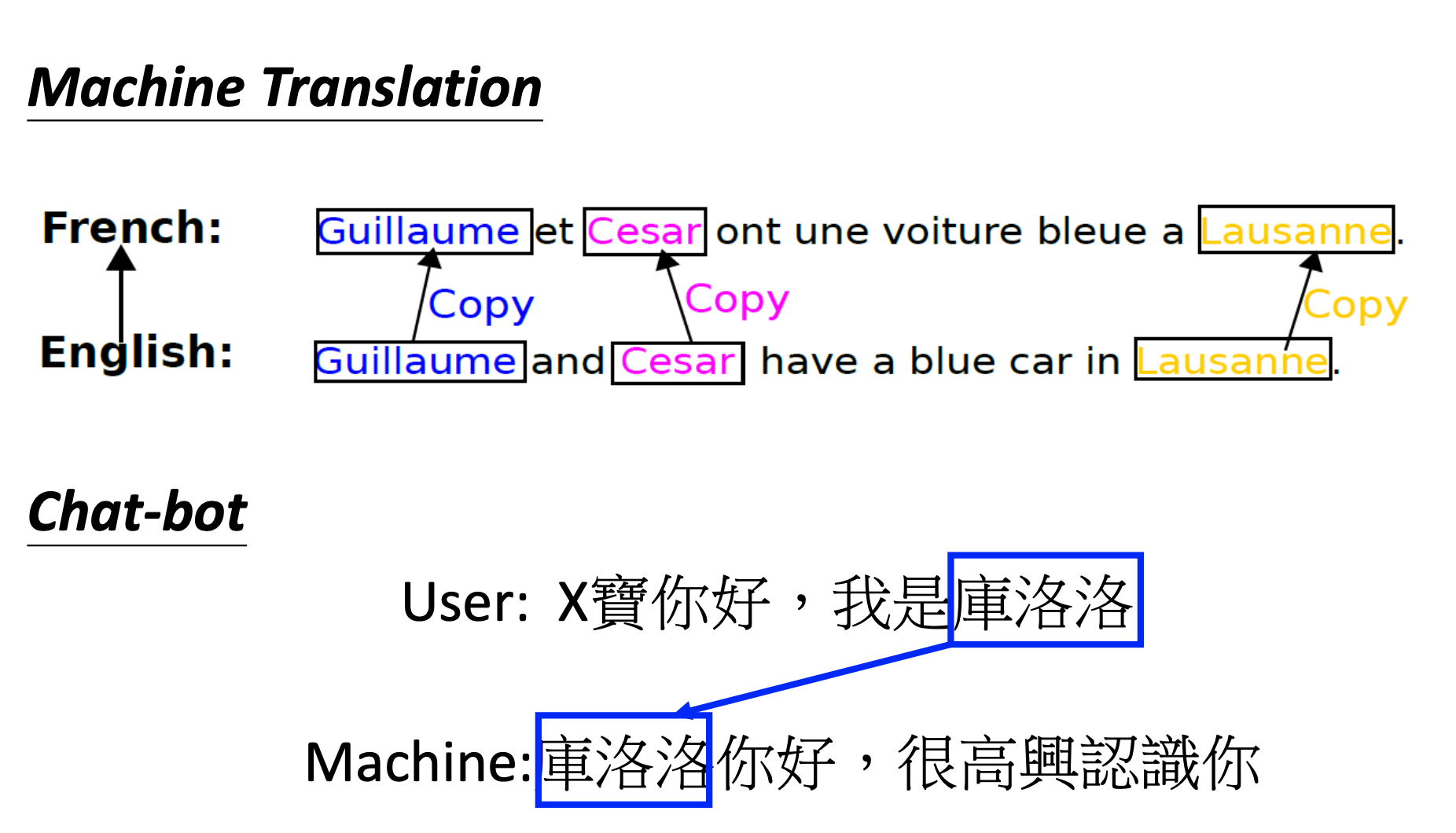
Copy Mechanism
In some cases, we may need the machine to simply copy some parts from the input sequence. ref
Guided Attention
In some tasks, input and output are monotonically aligned. For example, speech recognition, TTS, etc. For these tasks, we may want to force the scope of attention to move in a continuous manner.
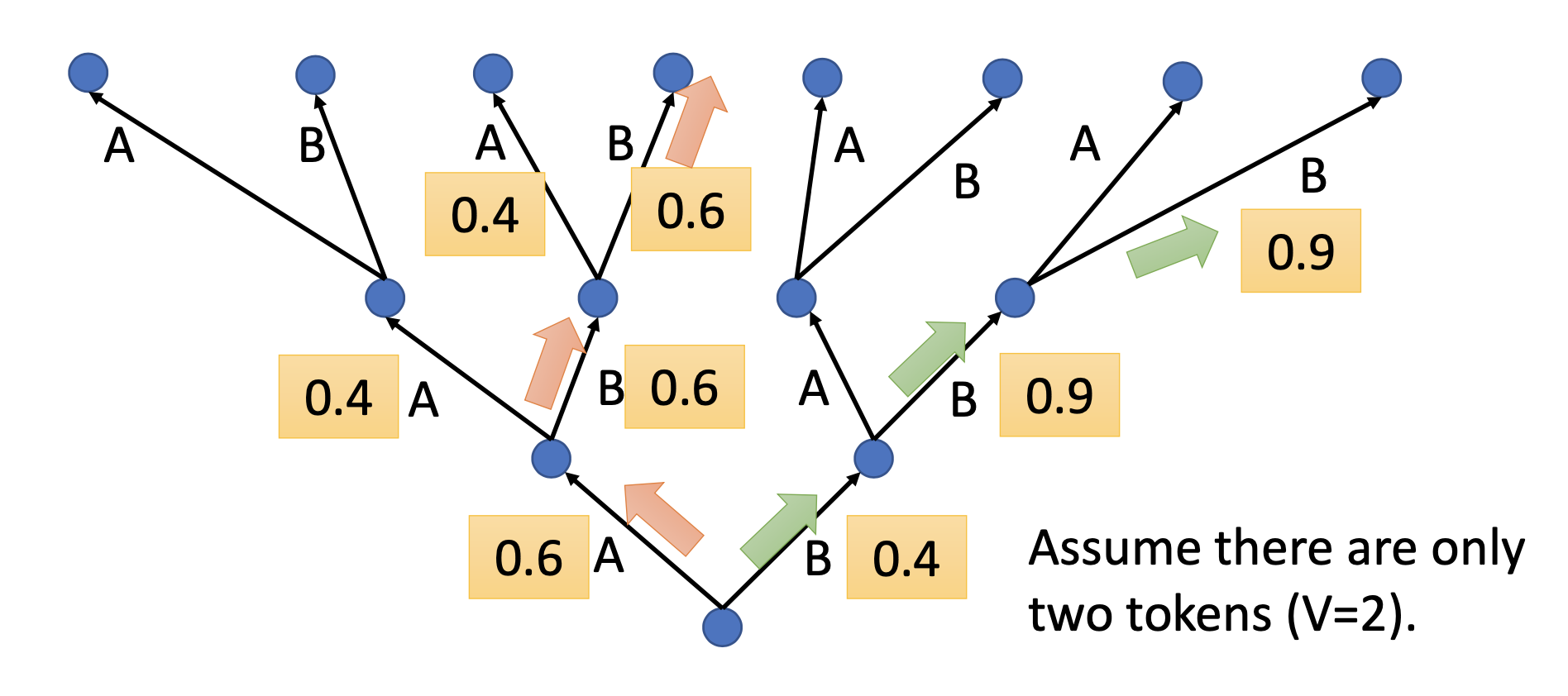
Beam Search
If we simply choose the output token with the highest probability, we are performing greedy decoding, like the red path in the figure below. However, the greedy decoding may fail to find the best path. We can use beam search to find the best path approximately. Beam search may benefit the tasks that we have only one possible output for an input or the outputs are somewhat fixed, e.g. speech recognition. On the other hand, beam search may also degrade the performance for the tasks that we want the machines to have some creativity, e.g. paragratph completion (ref).
References
Youtube【機器學習2021】Transformer (上)