Notes for Prof. Hung-Yi Lee's ML Lecture: Normalization
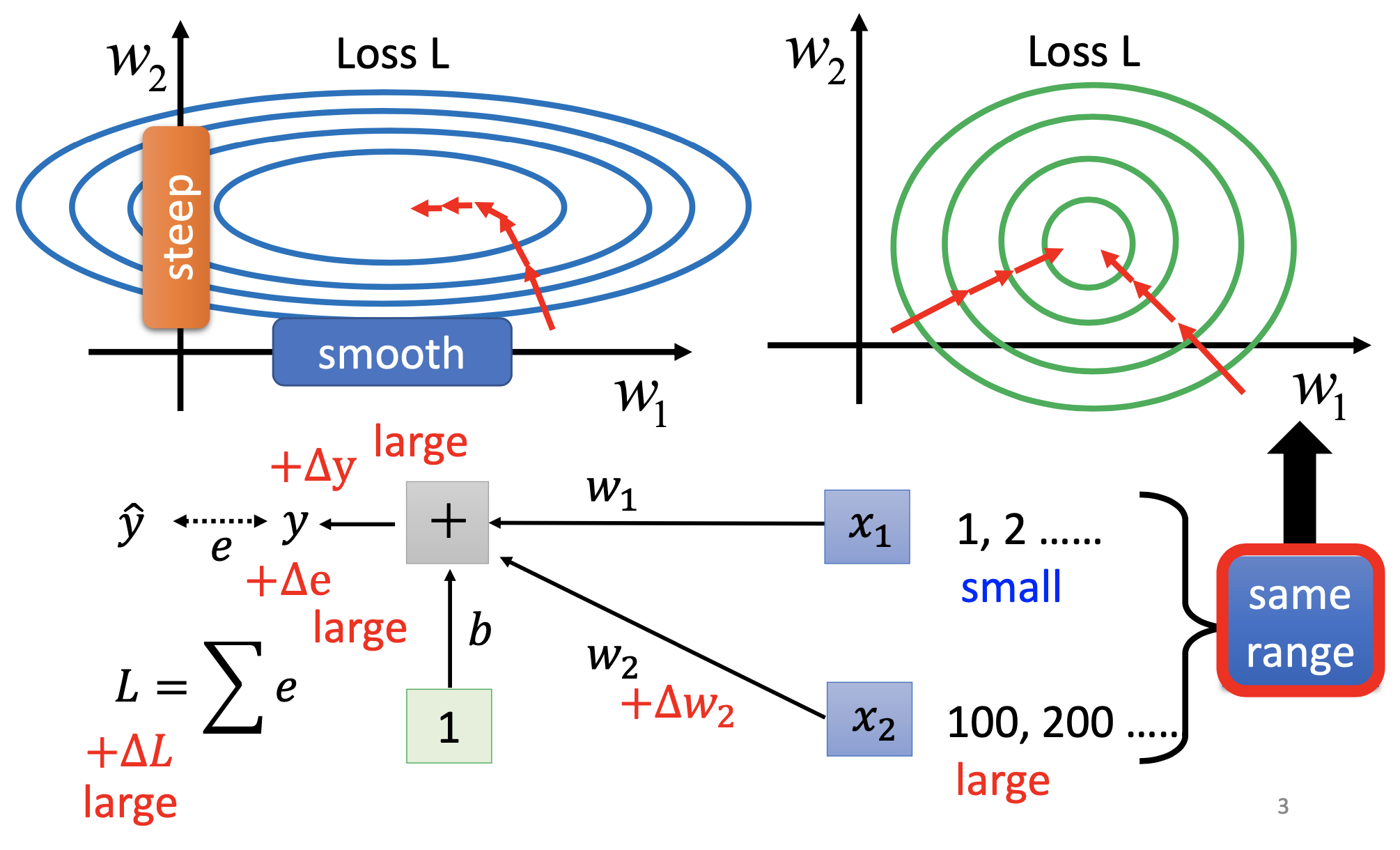
Normalization and Error Surface
Like the left part of the figure, the error surface may be steep for some parameters while flat for some others, and such situation cause sifficulties for gradient descent. By normalization, we made the slope of the error surface to different parameters more uniform to make gradient descent converge faster, like the right part of the figure.
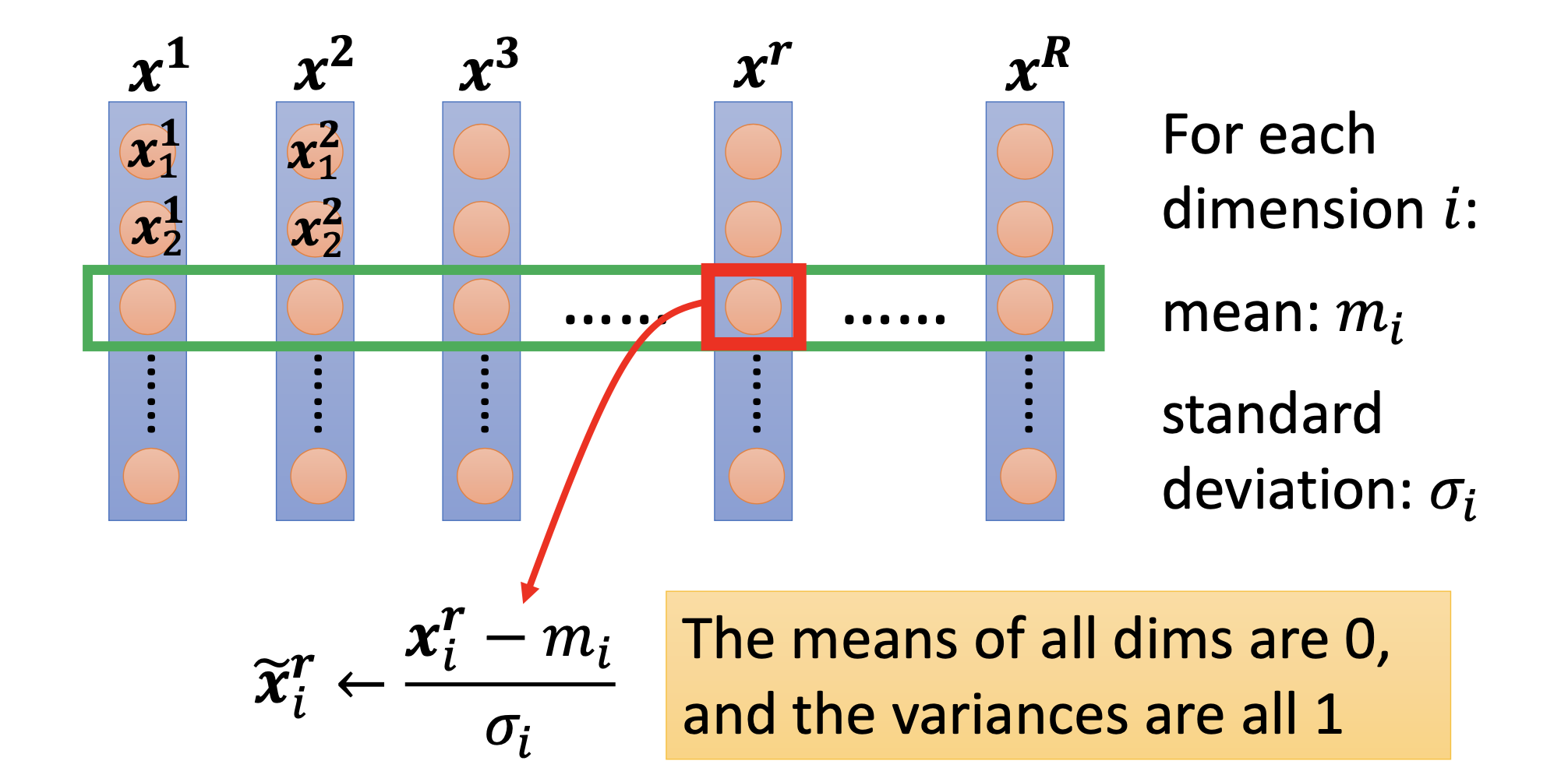
Feature Normalization
By feature normalization, we normalize each feature dimension over all samples.
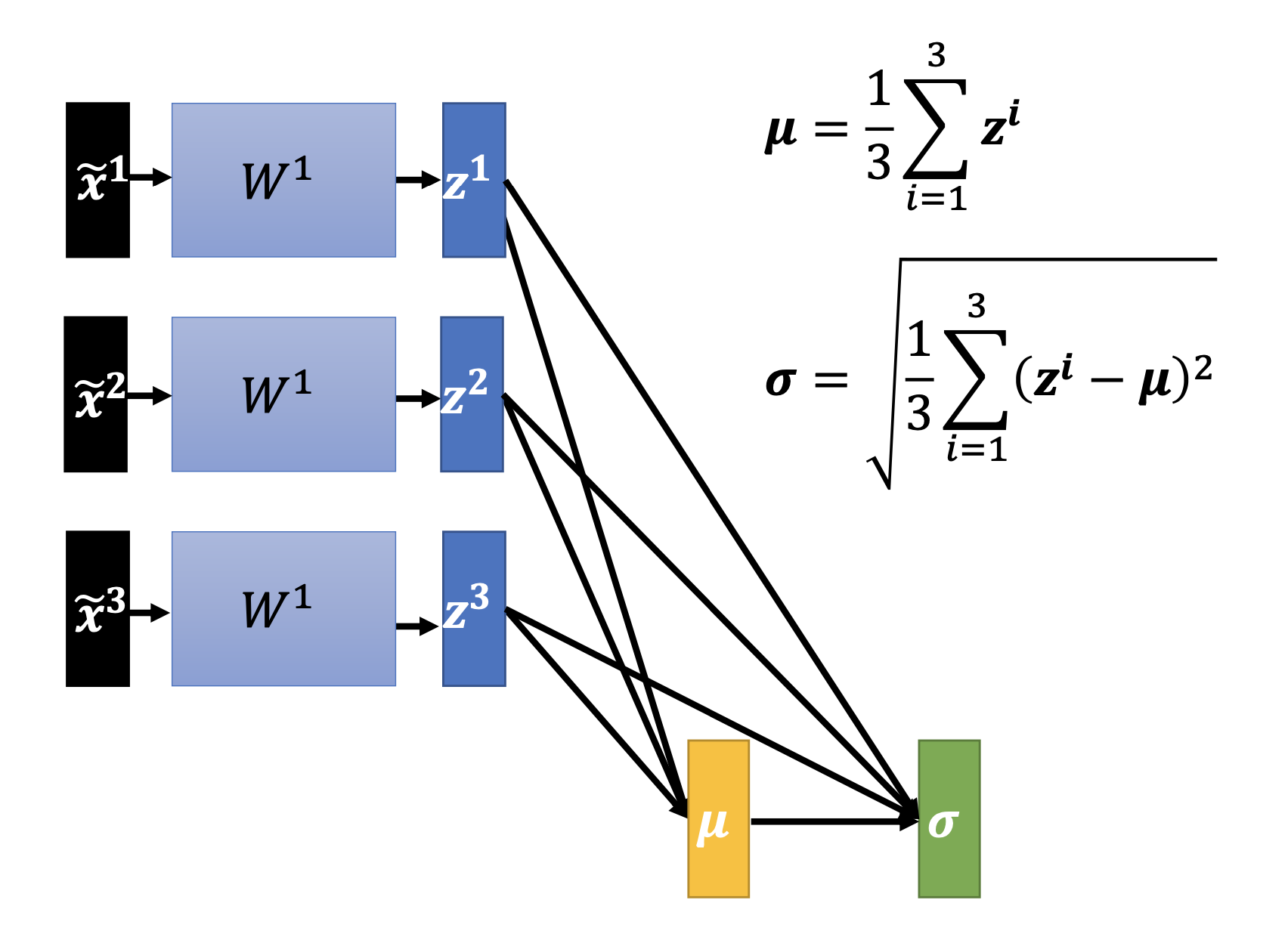
Batch Normalization
By batch normalization, we normalize all dimensions of the the hidden-layer vectors over all samples.
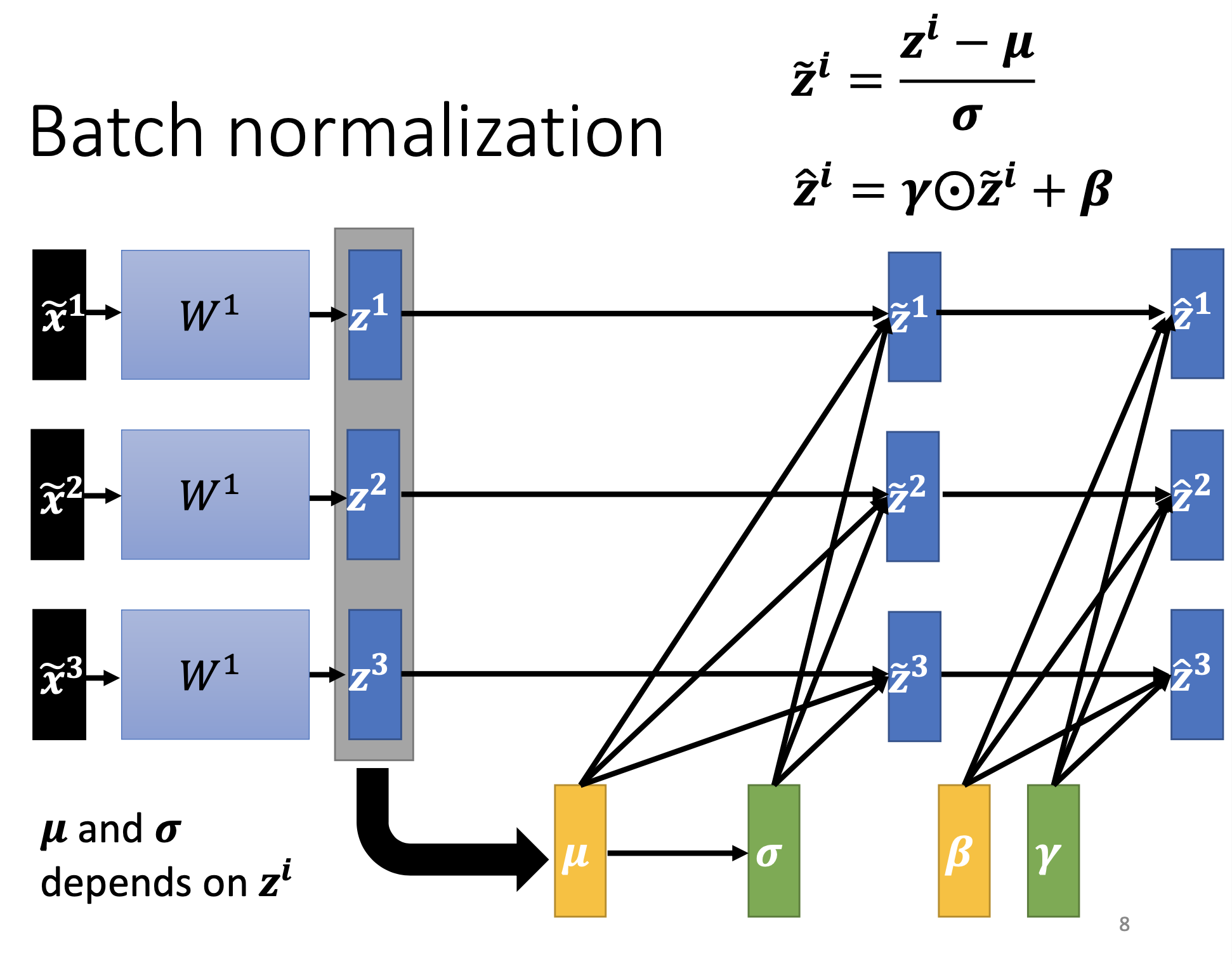
Moreover, since the normalization limit the distributions of the vectors, we furthen introduce parameters $\beta$ and $\gamma$ to allow variations on mean and standard deviation. $\beta$ and $\gamma$ will be trained.
When inferencing, there are no batches, so we use the moving average of the mean and sigma computed in training. The moving average can be computed by, for example,
\[\bar{\mu} \gets p \bar{\mu} + (1-p) \mu^{t}\]where t is the number of epochs, p is a number between $0$ and $1$.
References
Youtube 【機器學習2021】類神經網路訓練不起來怎麼辦 (五): 批次標準化 (Batch Normalization) 簡介