Notes for Prof. Hung-Yi Lee's ML Lecture: Ensemble
Ensemble: Bagging
By Bagging, we create multiple training data sets from the original training data set, train multiple models, and combine all the trained models for inference. For classification, we can use voting as the methodology of the combination; for regression, we can use averaging as the methodology.
Bagging may be helpful when our model is complex and easy to overfit. In other words, bagging is for reducing the error from variance of the model. Bagging is for the strong models.
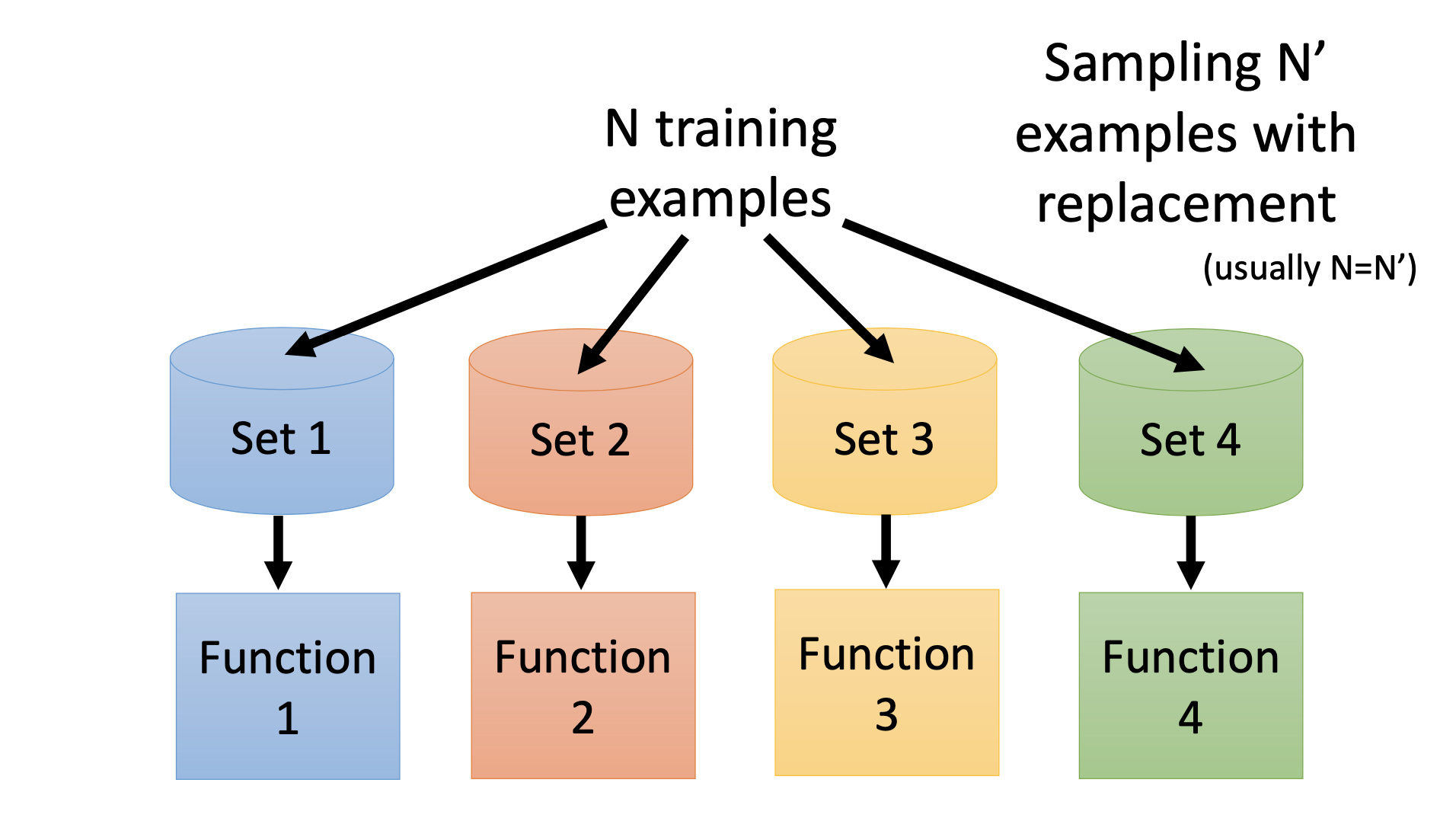
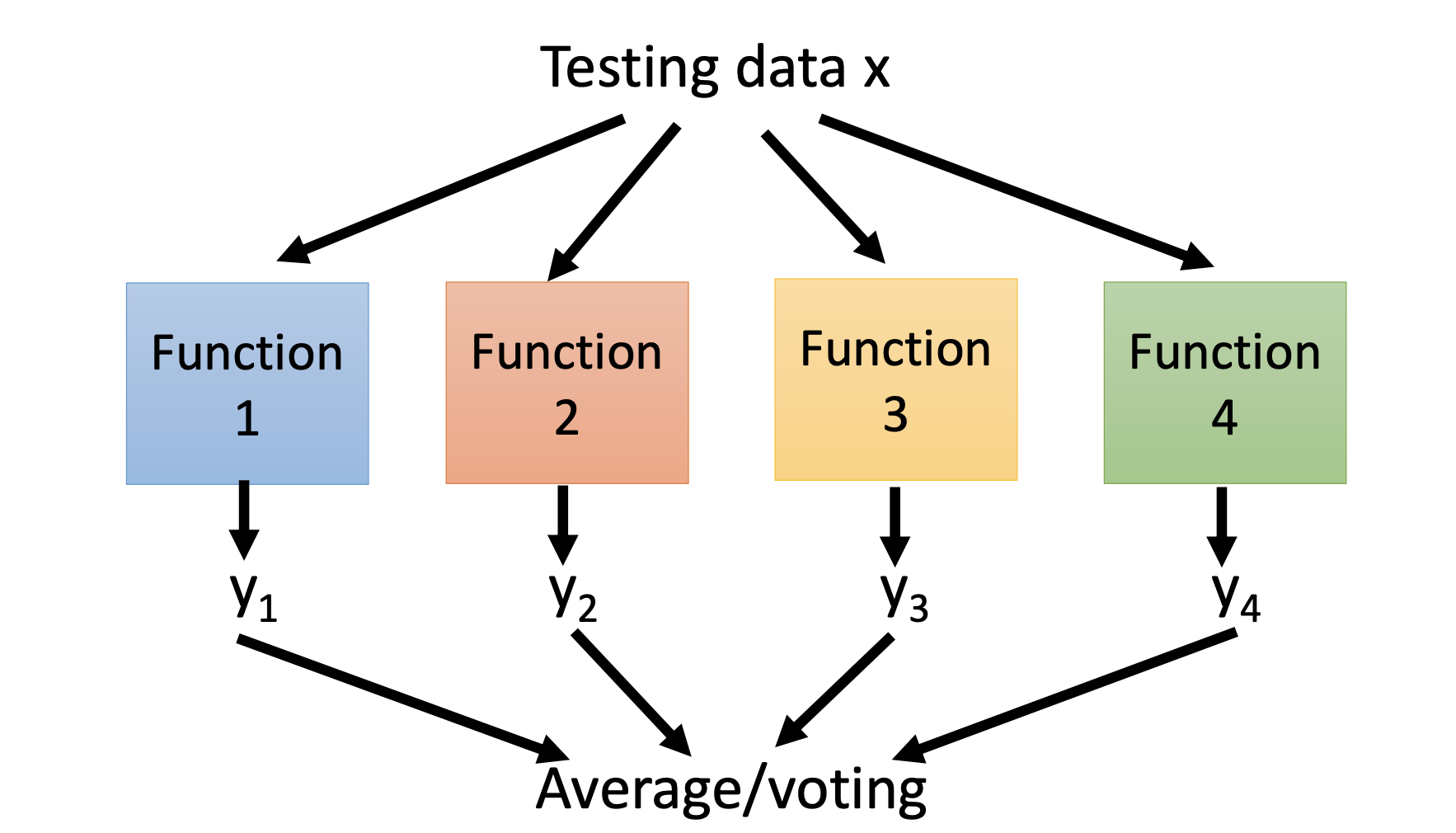
Random forest is the decision tree with bagging.
Ensemble: Boosting
Boosting is for the weak models.
Guarantee: If your ML algorithm can produce classifier with error rate smaller than 50% on training data, then You can obtain 0% error rate classifier after boosting.
Framework of boosting:
- Obtain the first classifier $f_1(x)$.
- Find another function $f_2(x)$, which is complementary with $f_1(x)$.
- …… Find another classifier $f_n(x)$
- Combine all the classifiers.
To obtain different classifiers, we can create new training sets by re-sampling or re-weighting the training. In real implementation, you only have to change the cost/objective function. For example, we multiply weights for each data points
\[L(f) = \sum_n l(f(x^n), \hat{y}^n) \to L(f) = \sum_n \mu_n l(f(x^n), \hat{y}^n)\]By boosting, the classifiers are learned sequentially. Not like bagging, where the classifiers can be learned independently.
Adaboost
Idea: to train $f_{n}(x)$ on the new training set that fails $f_{n-1}(x)$.

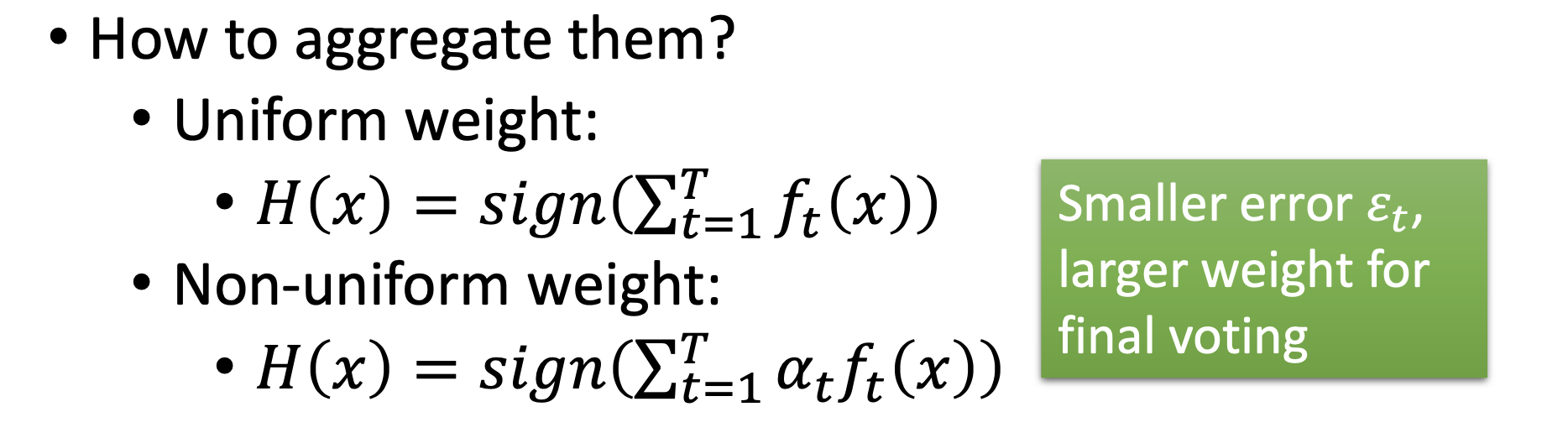
General Formulation of Boosting

Finding the $f_t(x)$s is gradient boostint. Adaboost is the gradient boosting with exponential loss function.
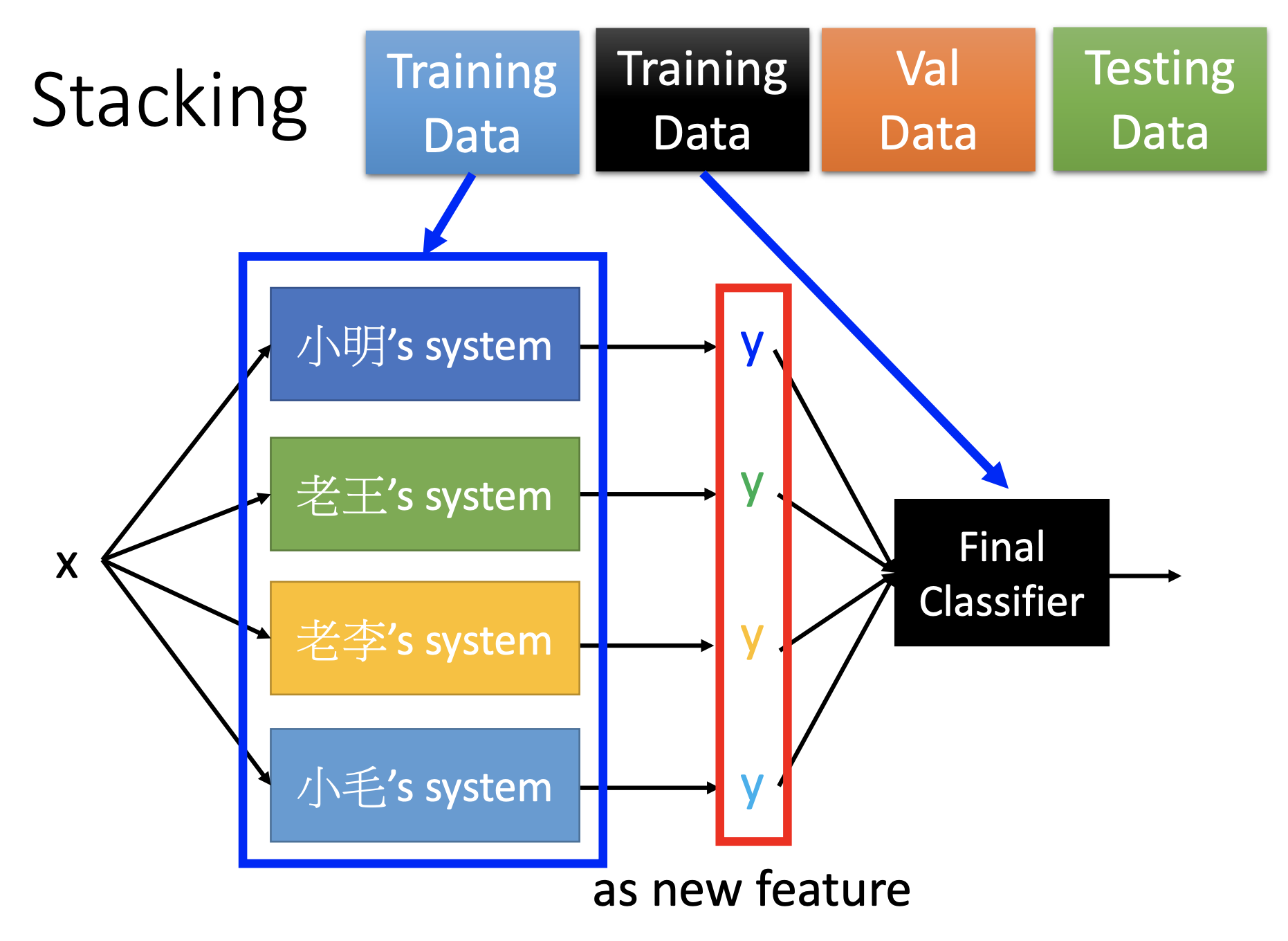
Stacking
To train a simple (e.g. logistic regression) final classifier for the trained classifiers for a final decision. By training such further classifier rather than simple voting, we can handle the cases that some of the trained classifiers may be very poor.