Notes for Prof. Hung-Yi Lee's ML Lecture: RNN
RNN
Structure & Operation
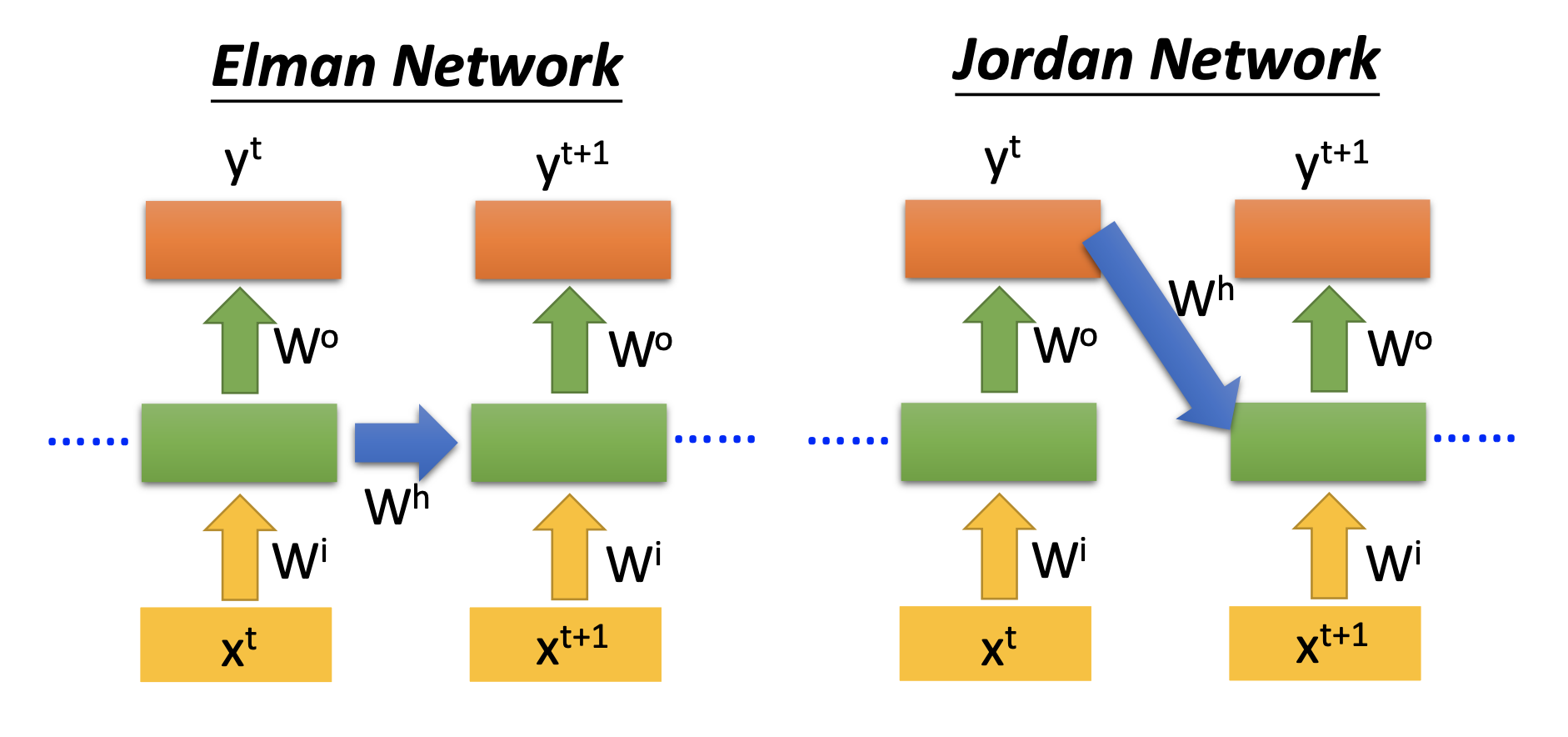
We can also make deep RNNs that have more than 1 layer of recurrent layers. Such simplest RNN is also named Elman network. There’s also Jordan network, which feed the output back into hidden layers. Jordan network may have better performance than Elman network because the output values are trained with a target, while a hidden layer is not.
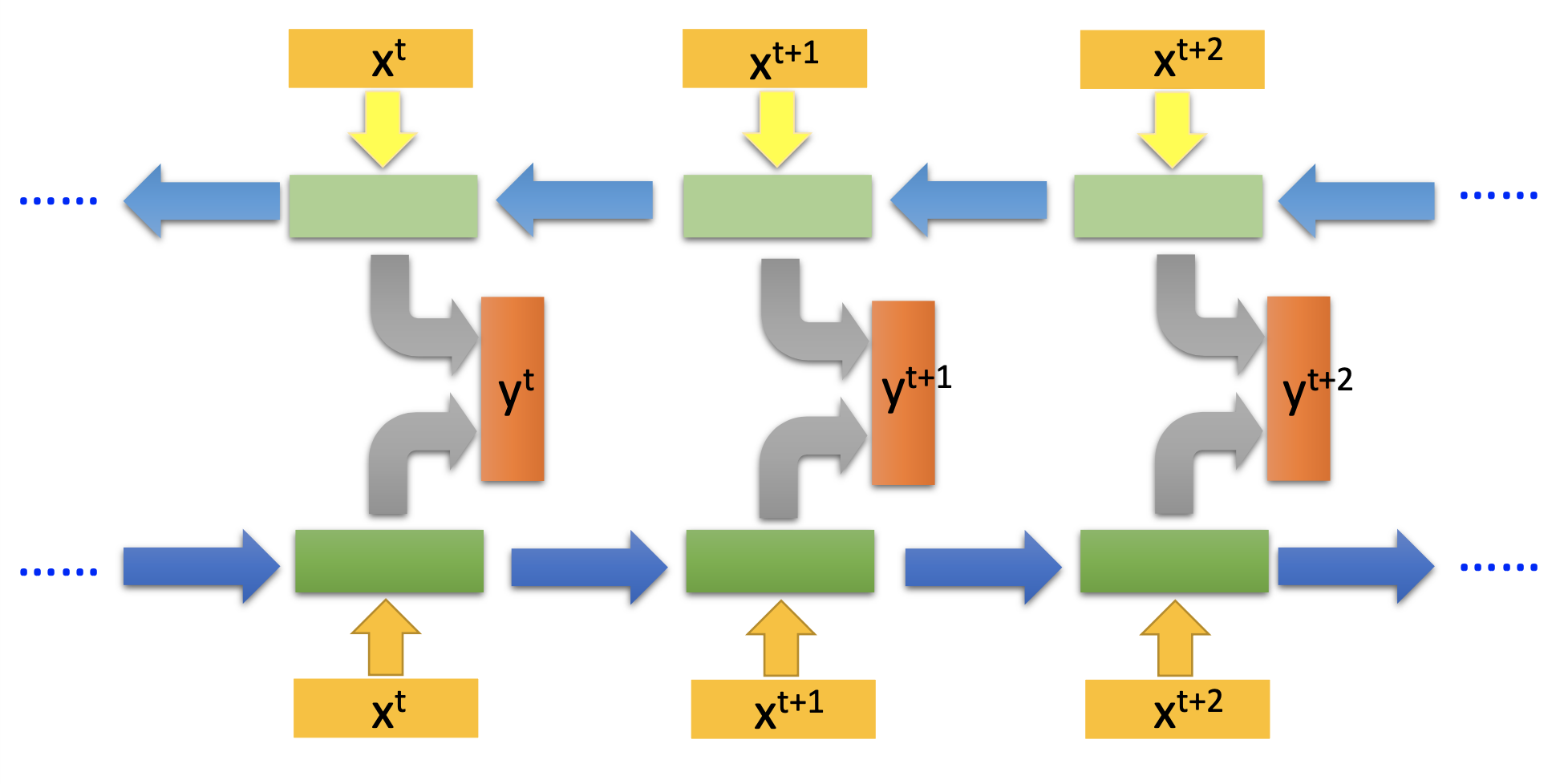
Bi-Directionsl RNN
To let the network be able to consider the whole input sequence when it produce the first output, we let 1 2nd network read the input sequence from the end to the beginning, and let sum of the 2 network’s output be the final output.
Long Short-Term Memory (LSTM)
Structure & Operation
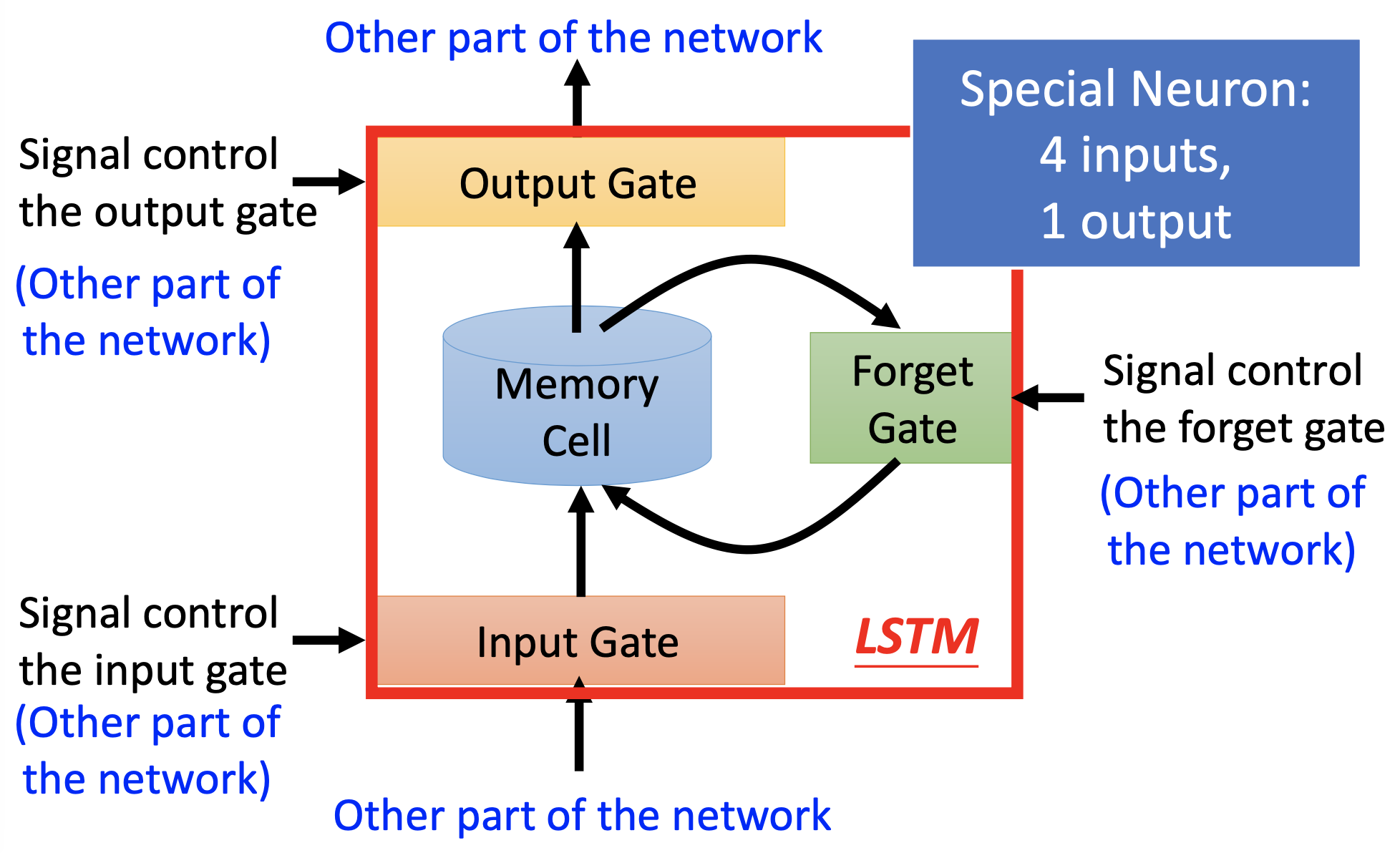
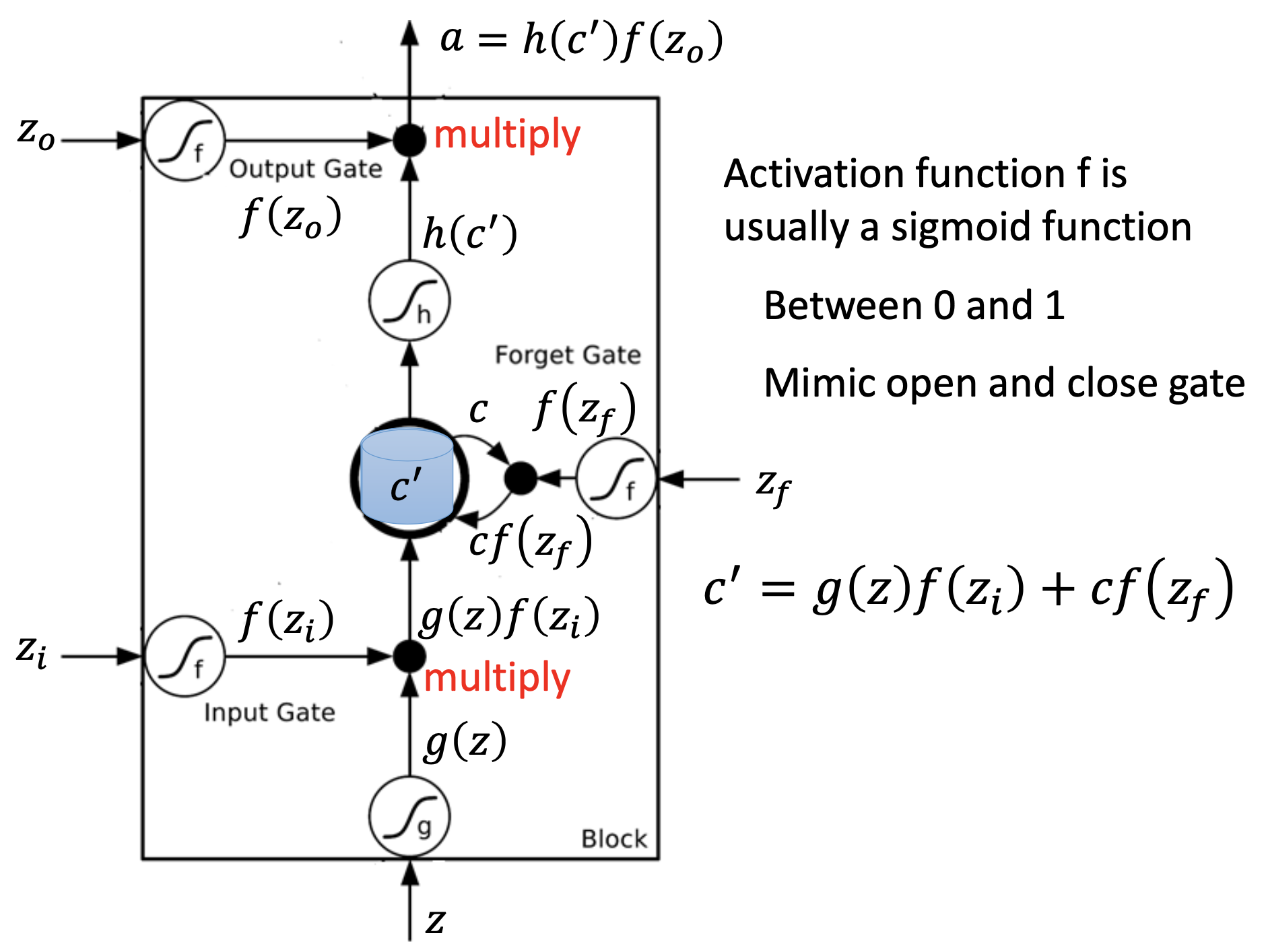
When $f(z_f) = 1$, the forget gate is on, then the memory $c$ is actually retained. The forget gate is actually works as a “retain gate”.
An LSTM neuton has 4 inputs, so an LSTM layer has 4 times of parameters than a notmal layer.
Training of any RNN is based on back propagation through time.
Furthermore, for the complete LSTM, we let the Peeehole and the output feed to the input of the next step.
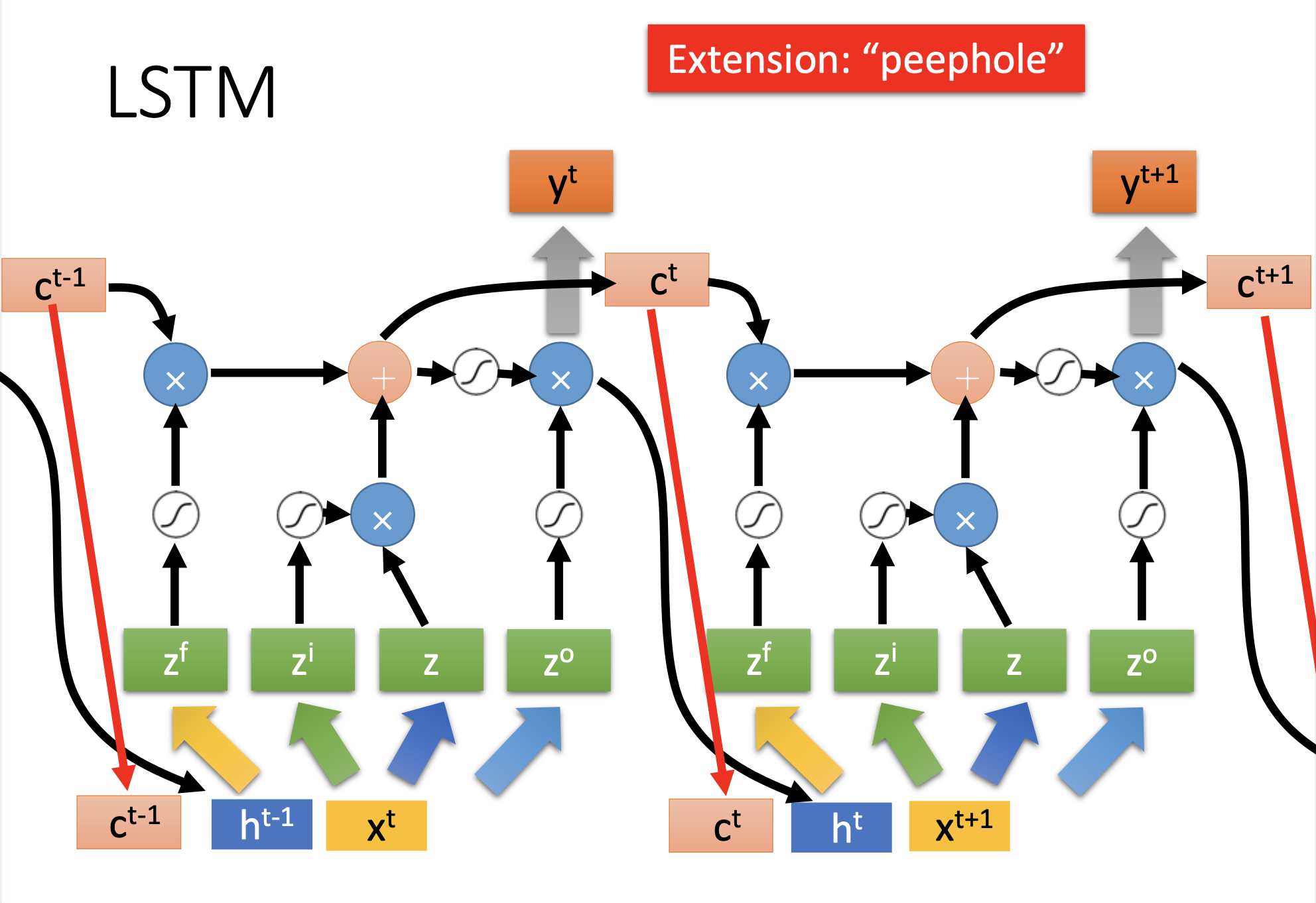
Discussion on Terminologies
The hiphen pythen should be between “short” and “term” because LSTM is a kind of short-term memory that is relatively longer; the memory may be either retained or removed.
Because LSTM is now the standard of RNN, people may mean “LSTM” when they say “RNN”. We can call the original simple RNN “Simple RNN” or “vanila RNN”.
Discussion on RNN Training
Training of Vanilla RNN may be difficult, for example, the loss may oscillate:
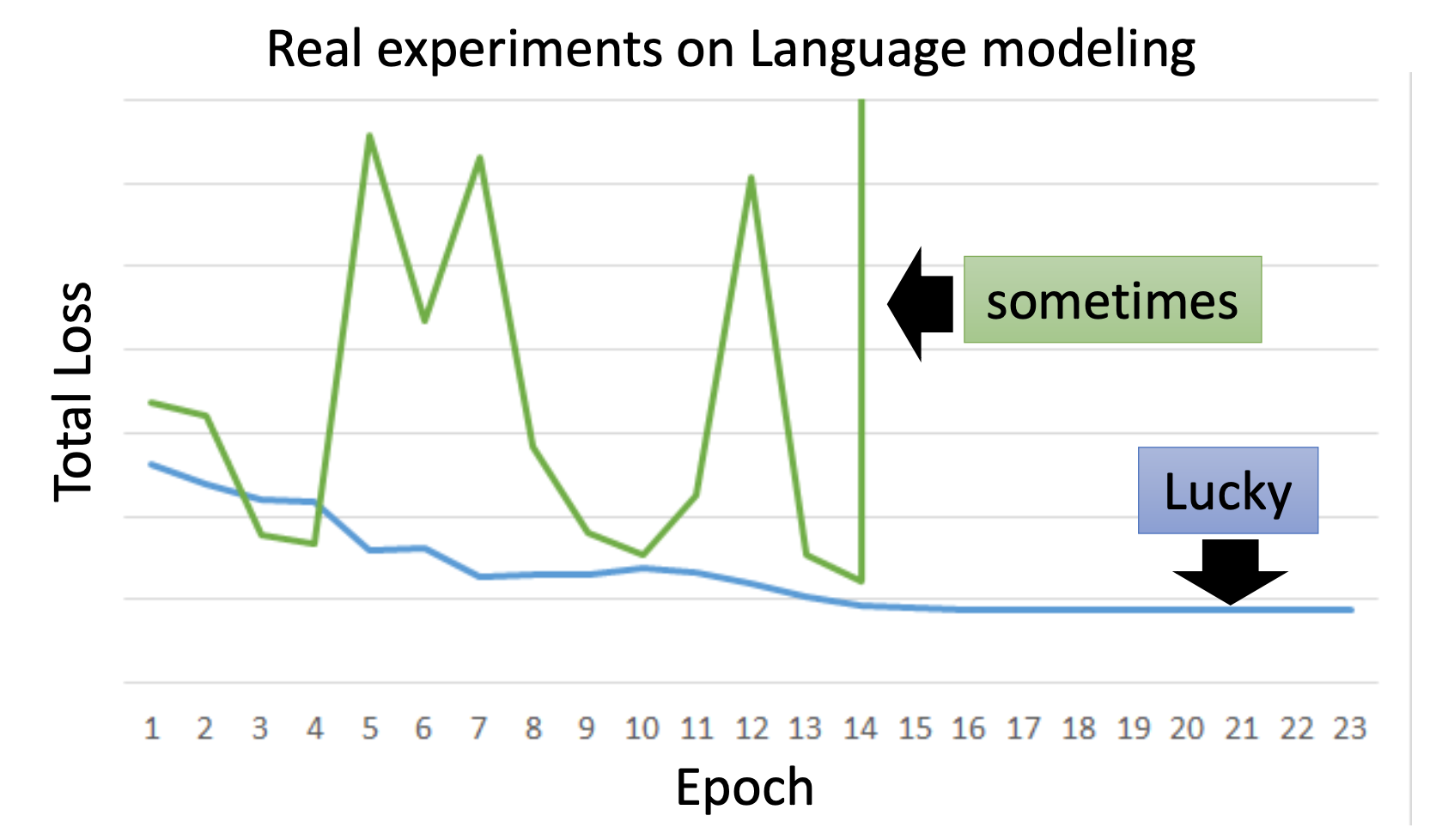
the reason is that the error surface is either very flat or very steep
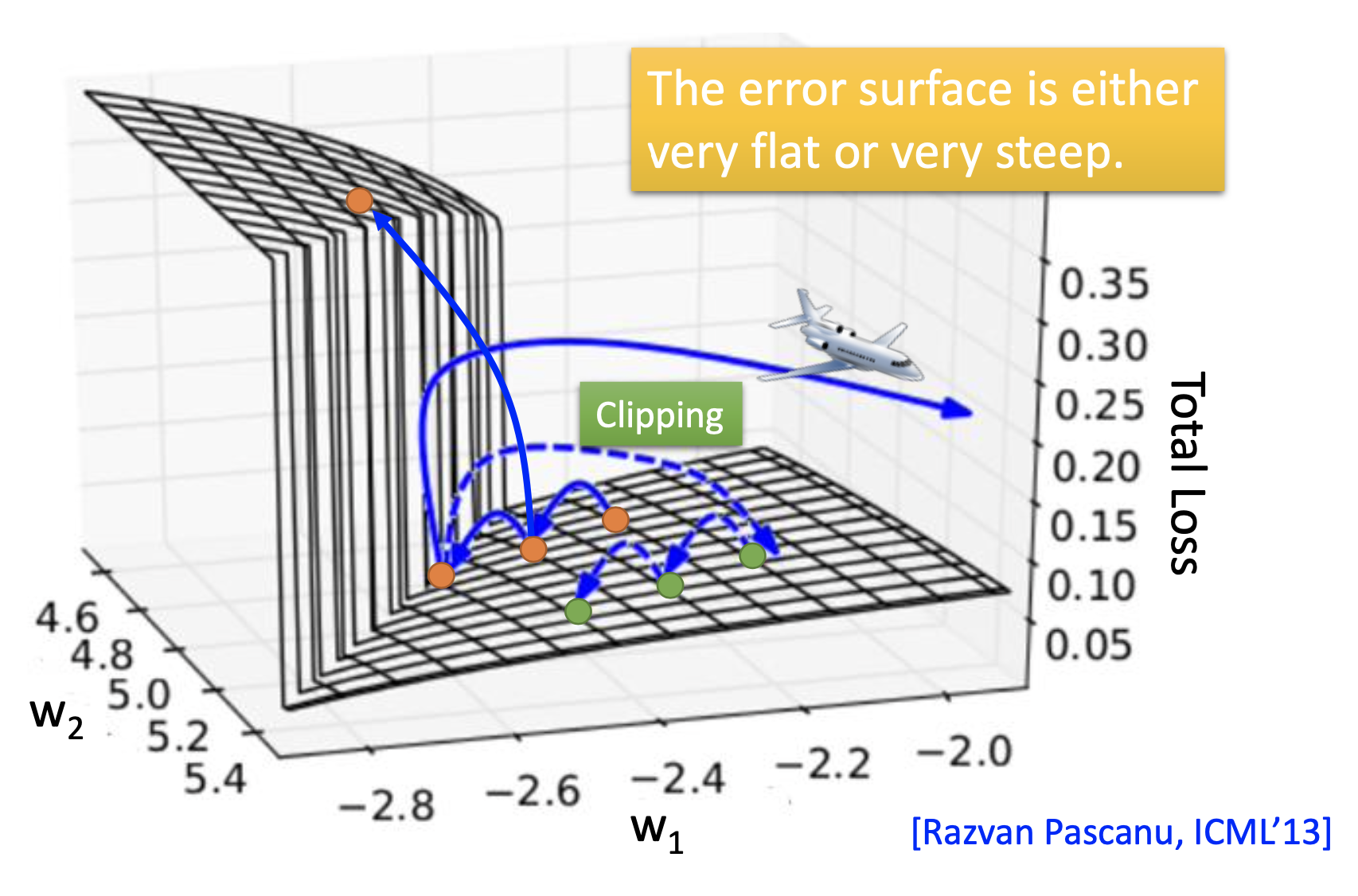
The sigmoid activation function is not the cause of the rough error surface; on RNN, ReLu is usually worse than sigmoid.
Actually, the reason is that the weights that propagate from the previous step to the next affect the final output exponentially, so its derivative to the loss can be extremely large or small.
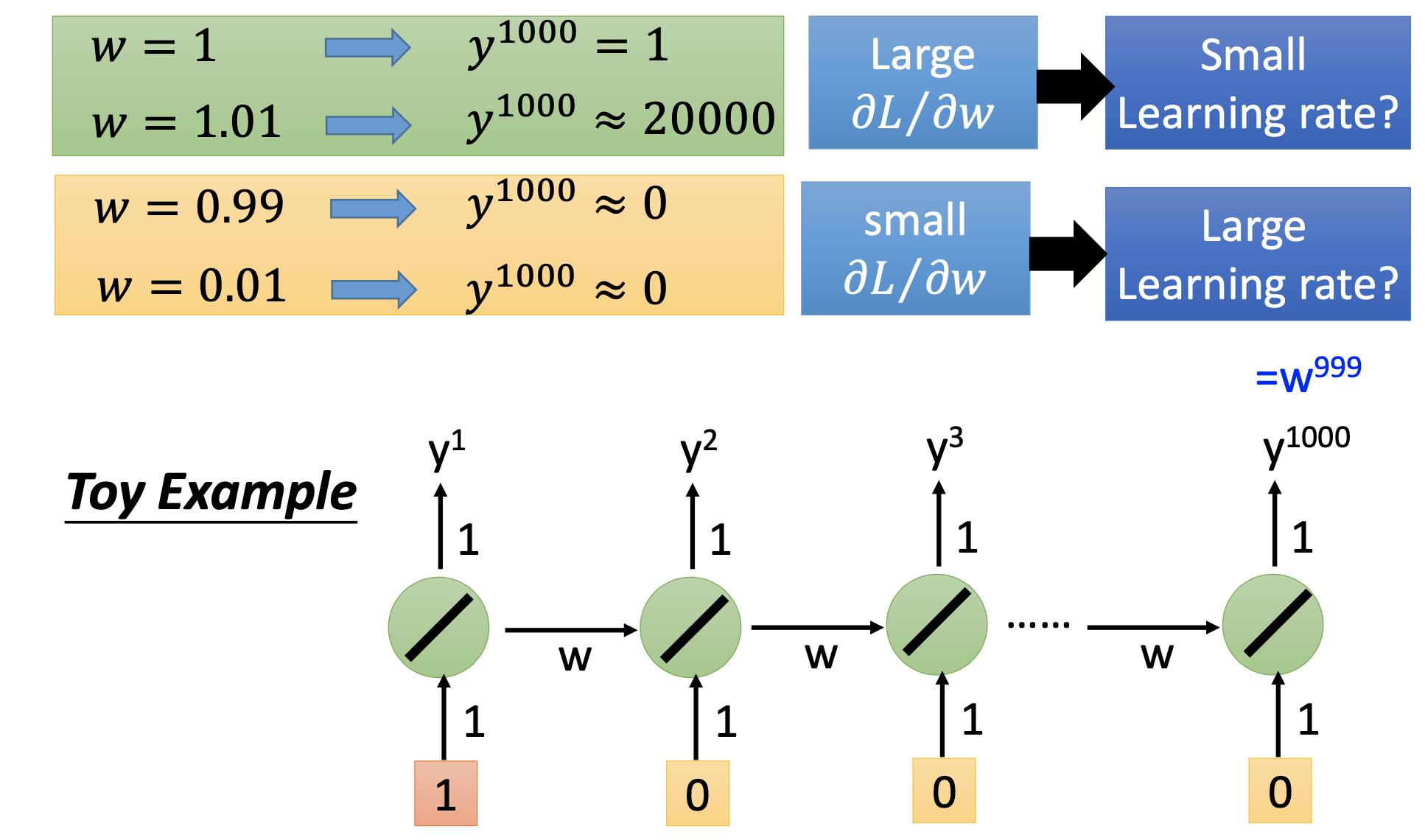
Clipping is a must when training RNNs to avoid get NaN values.
Another solution is replace vanilla RNN by LSTM. Because the memory and the new input are directly added, the influence never disappears unless forget gate is closed, which that the LSTM overcome the gradient vanishing (not gradient explosion). Without gradient vanishing, there’s no flat regions in the error surface, so we can safely use small learning rates. Actually, the motination of the earliest LSTM (without forget gate) is to handle the gradient vanishing.
Or, we can also use the smaller version of LSTM: Gated Recurrent Unit (GRU) [Cho, EMNLP’14]. GRU has less parameters, so it overfits less. By GRU, we just turn the forget off/on when the input gate is on/off.
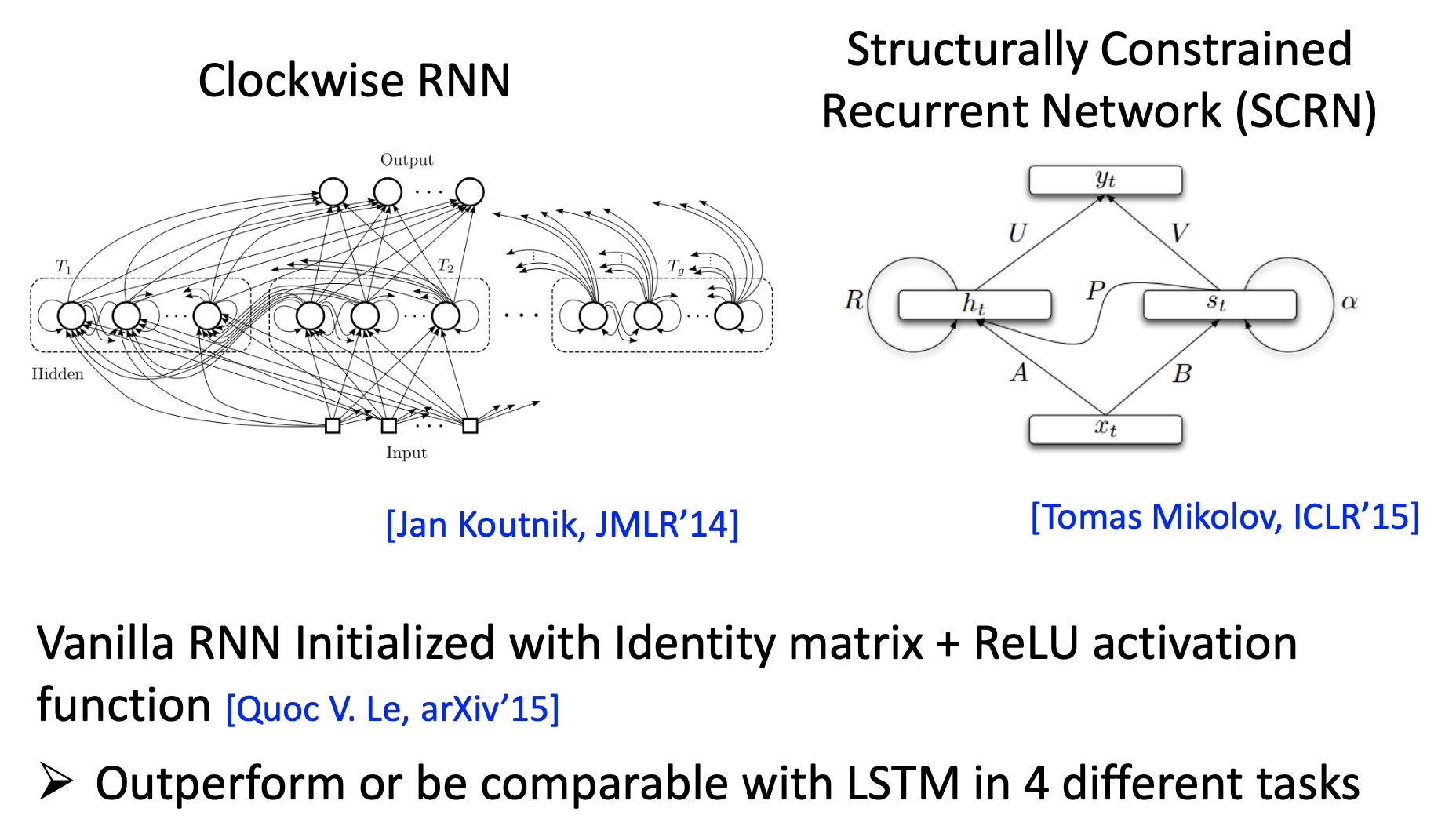
Other solutions
Applications
Many to Many with the Same Length
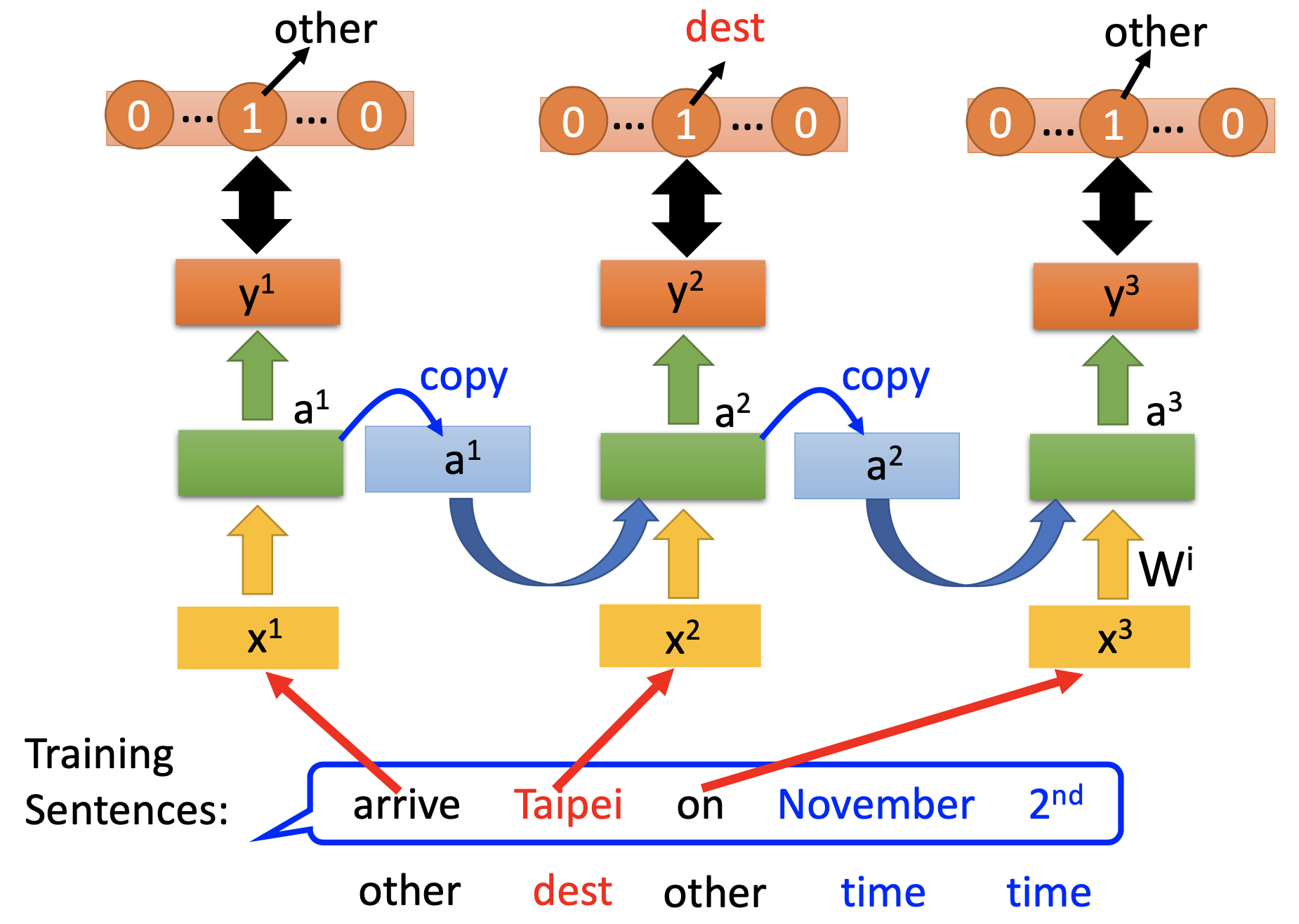
Slot Filling
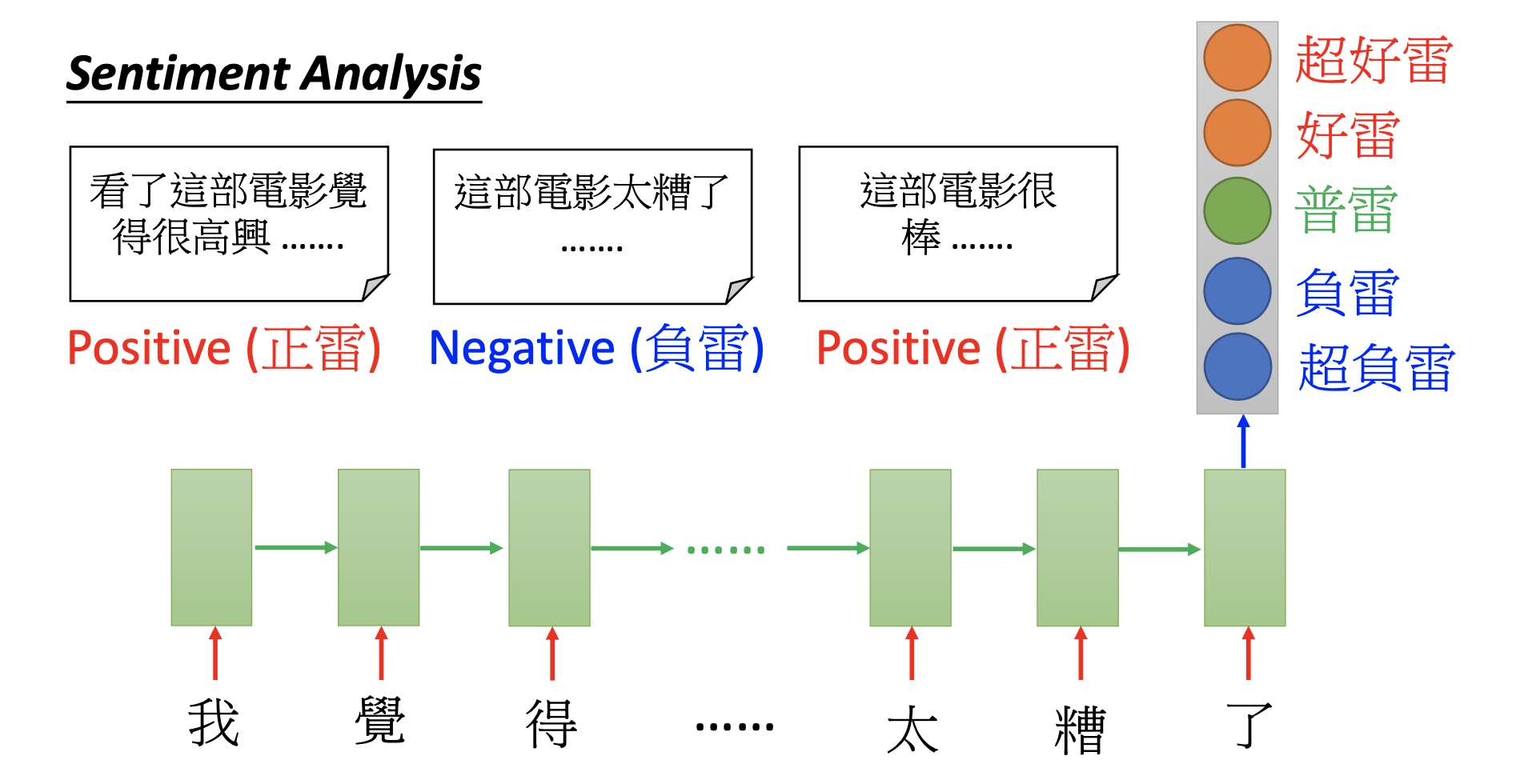
Many to One
Input is a vector sequence, but output is only one vector.
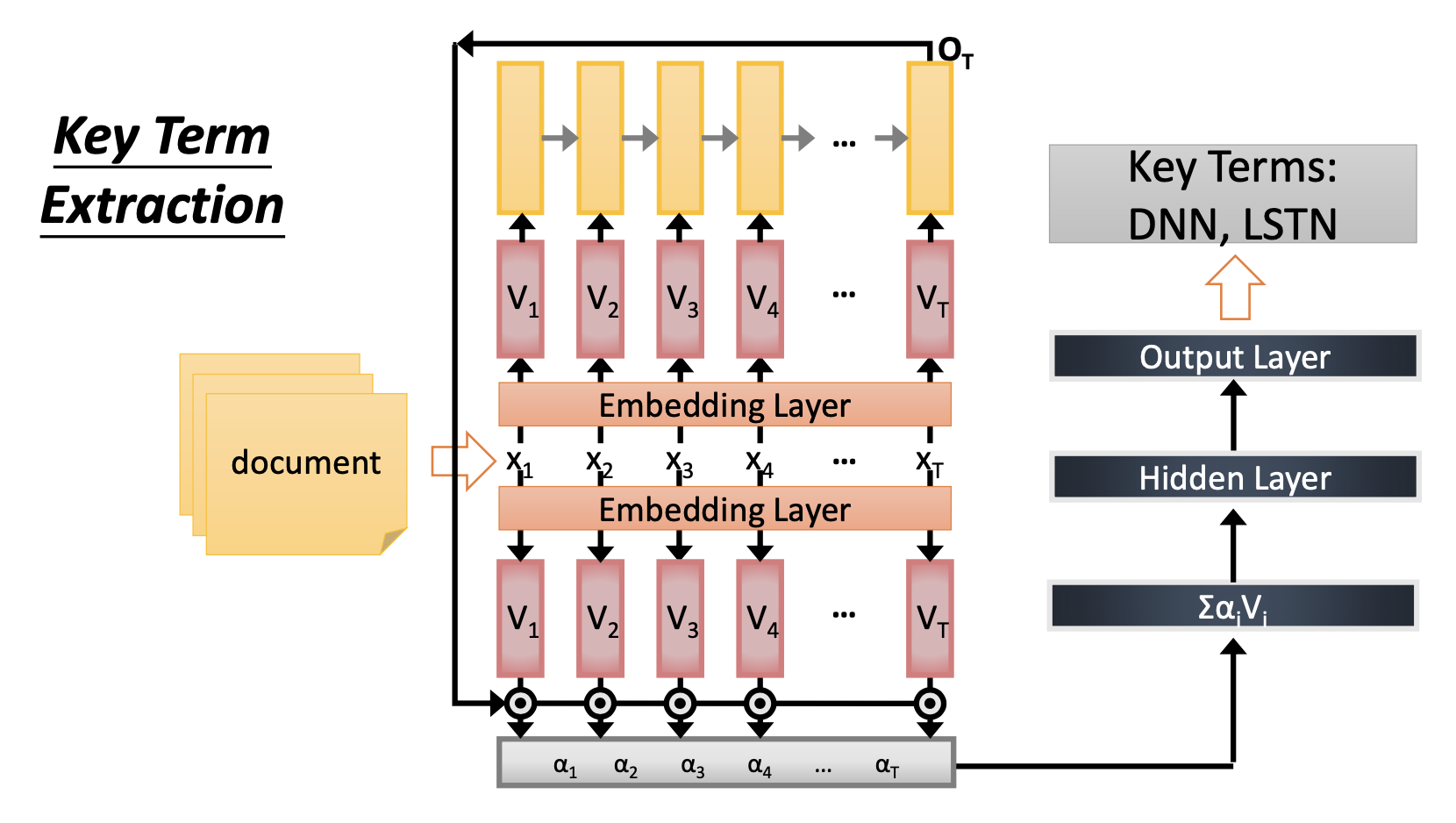
Many to Many (Output is shorter)
Speech Recognition
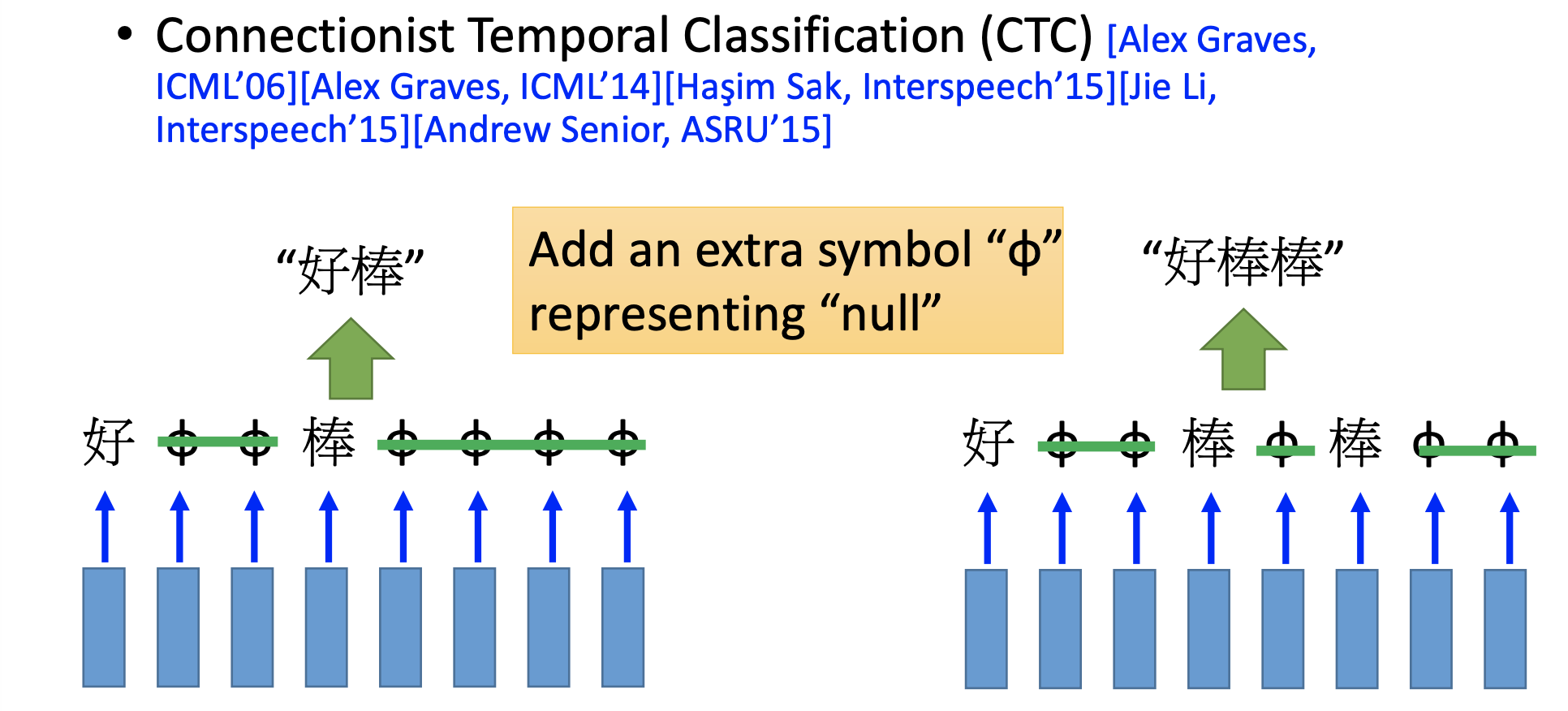
Many to Many (No Limitation)
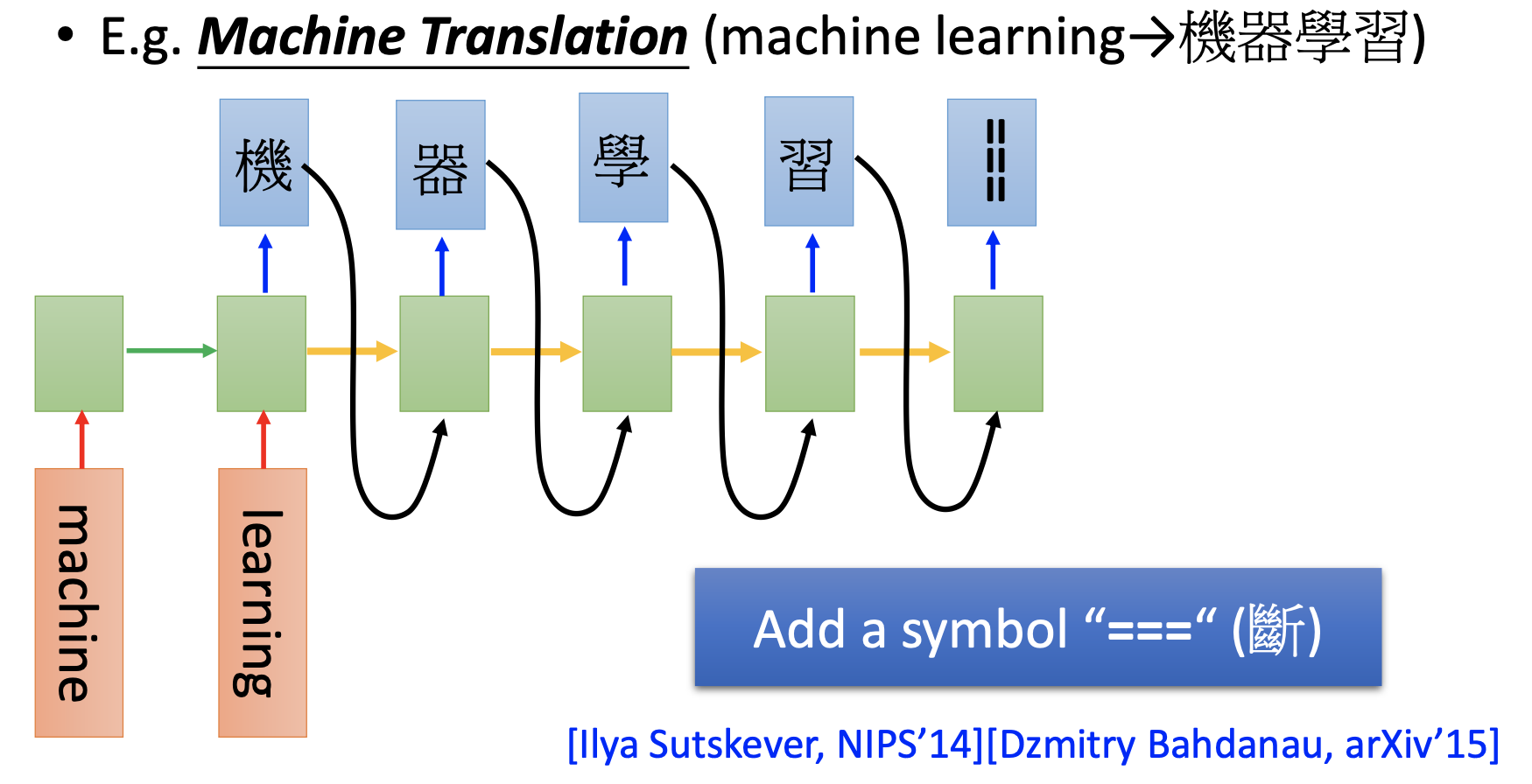
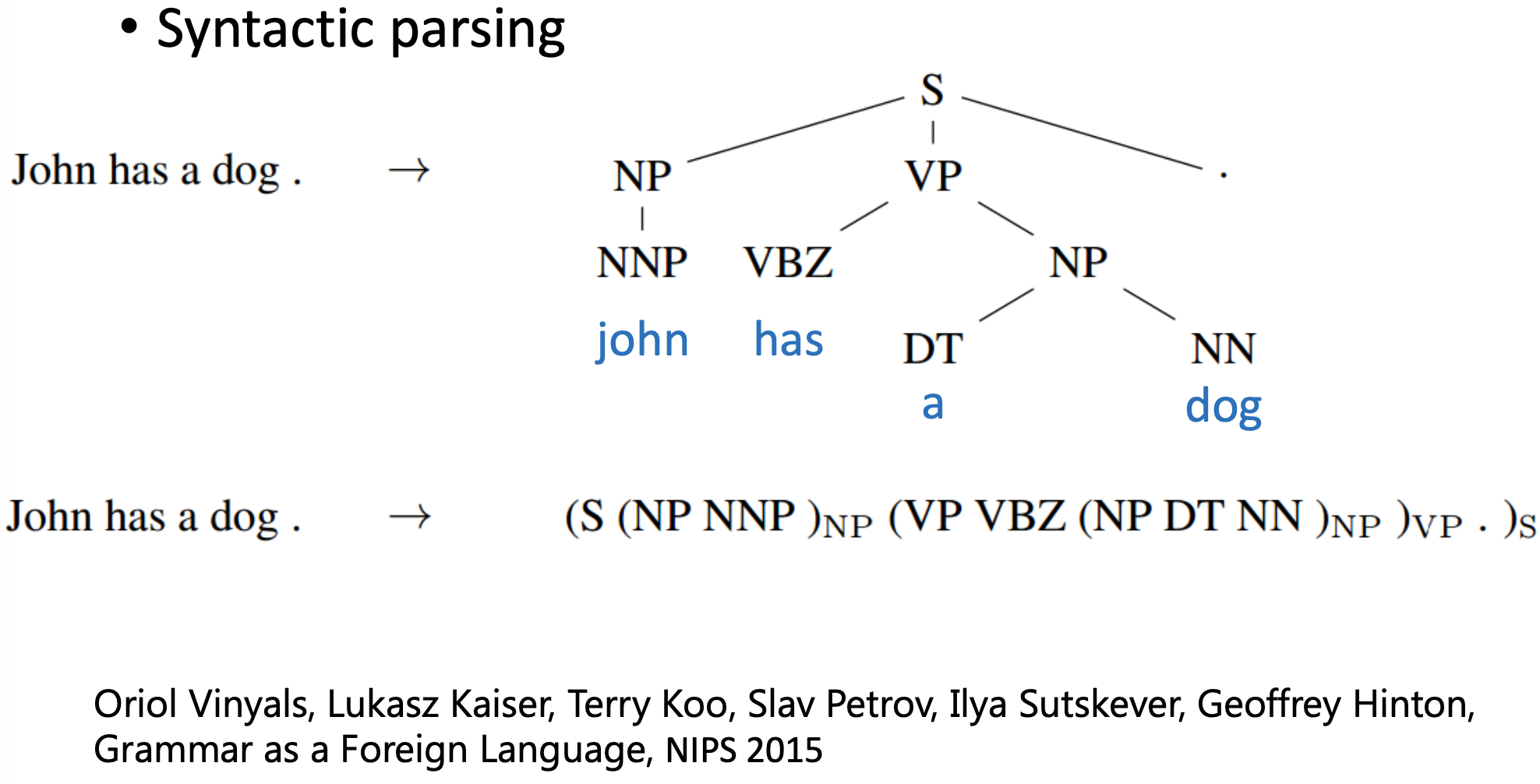
Auto-Encoder
The auto-encoder can be used for search.
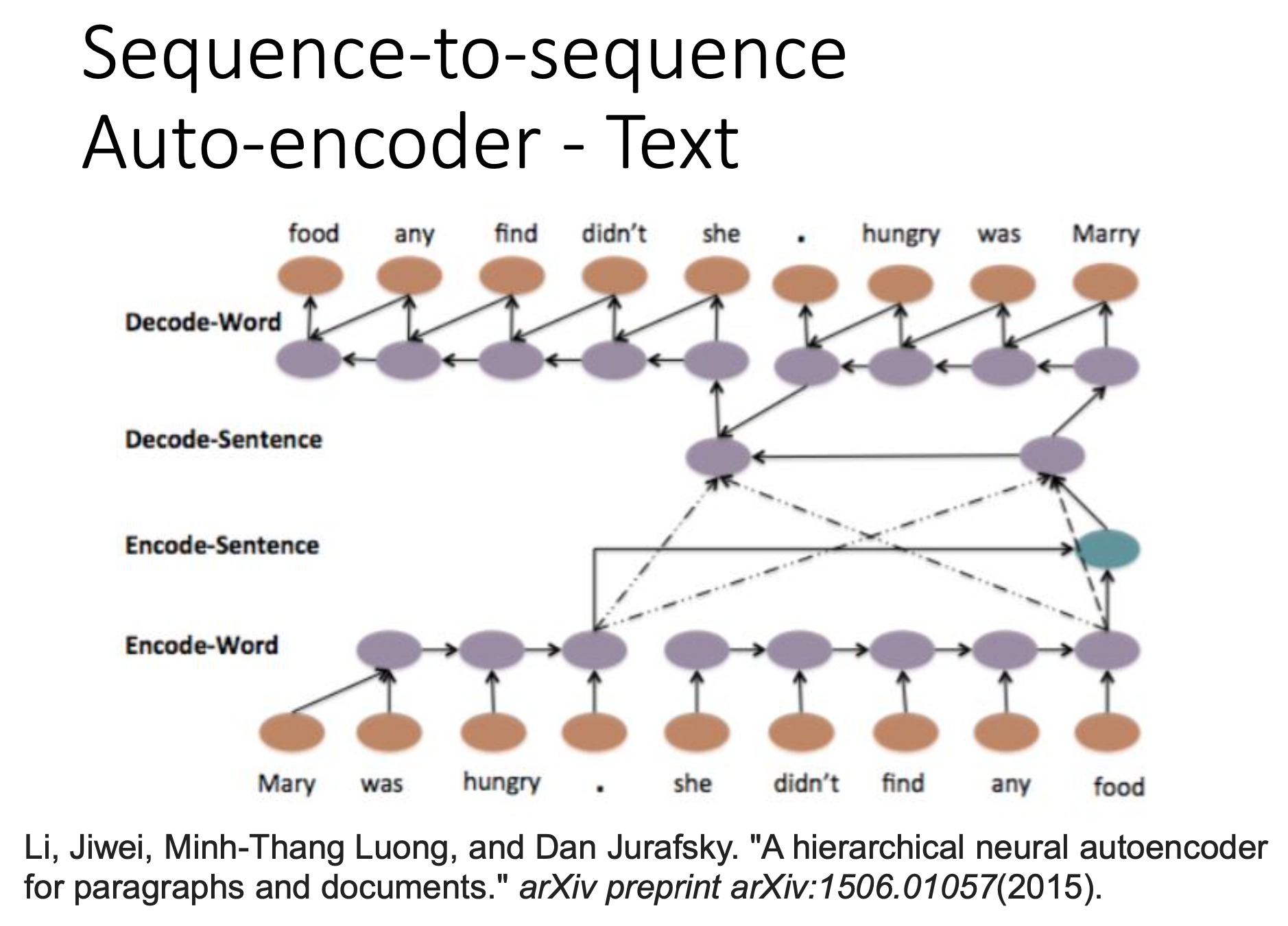
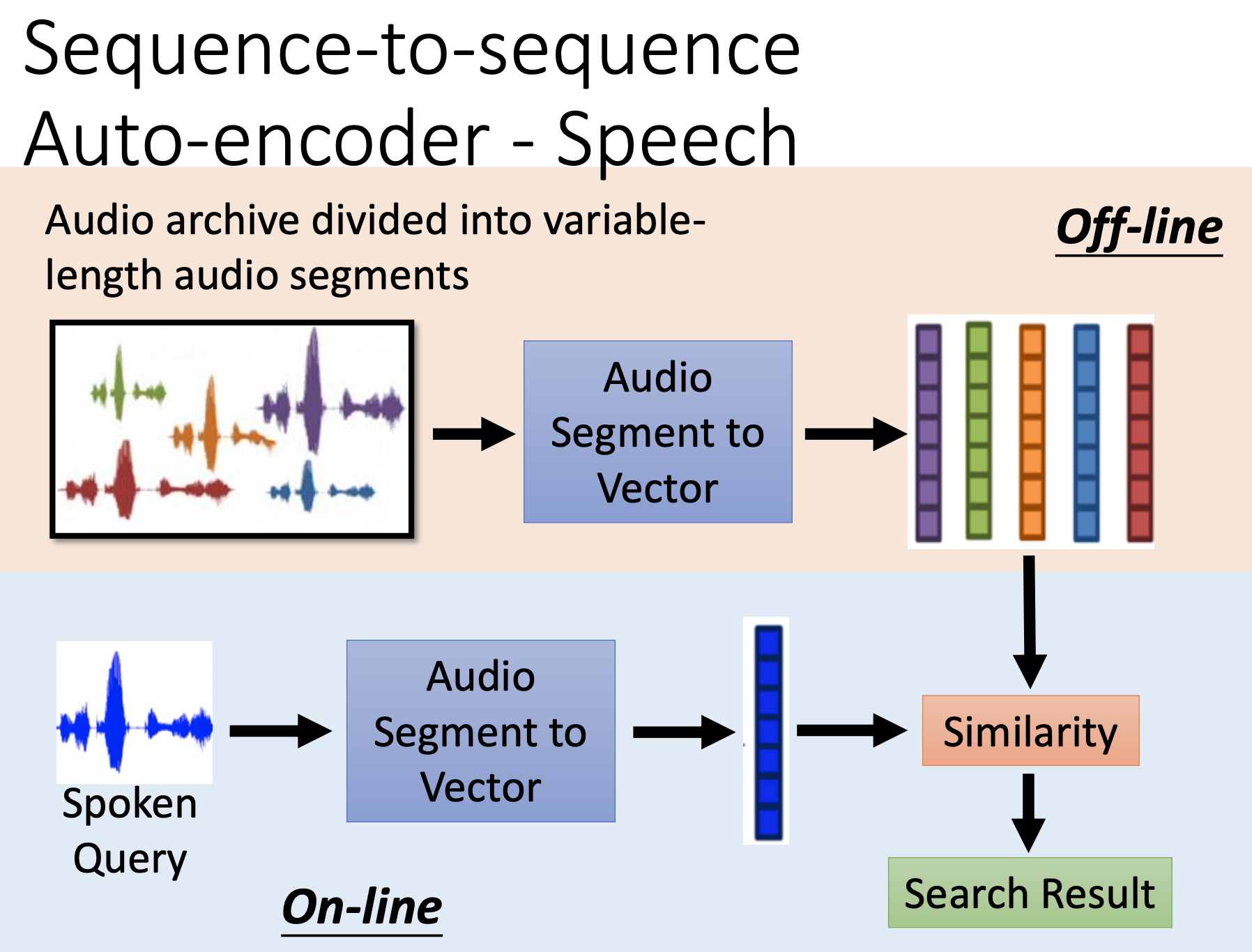
Besides, seq2seq auto-encoder tend to retrieve the information of grammar; skip-through tend to retrieve the information of sementics.
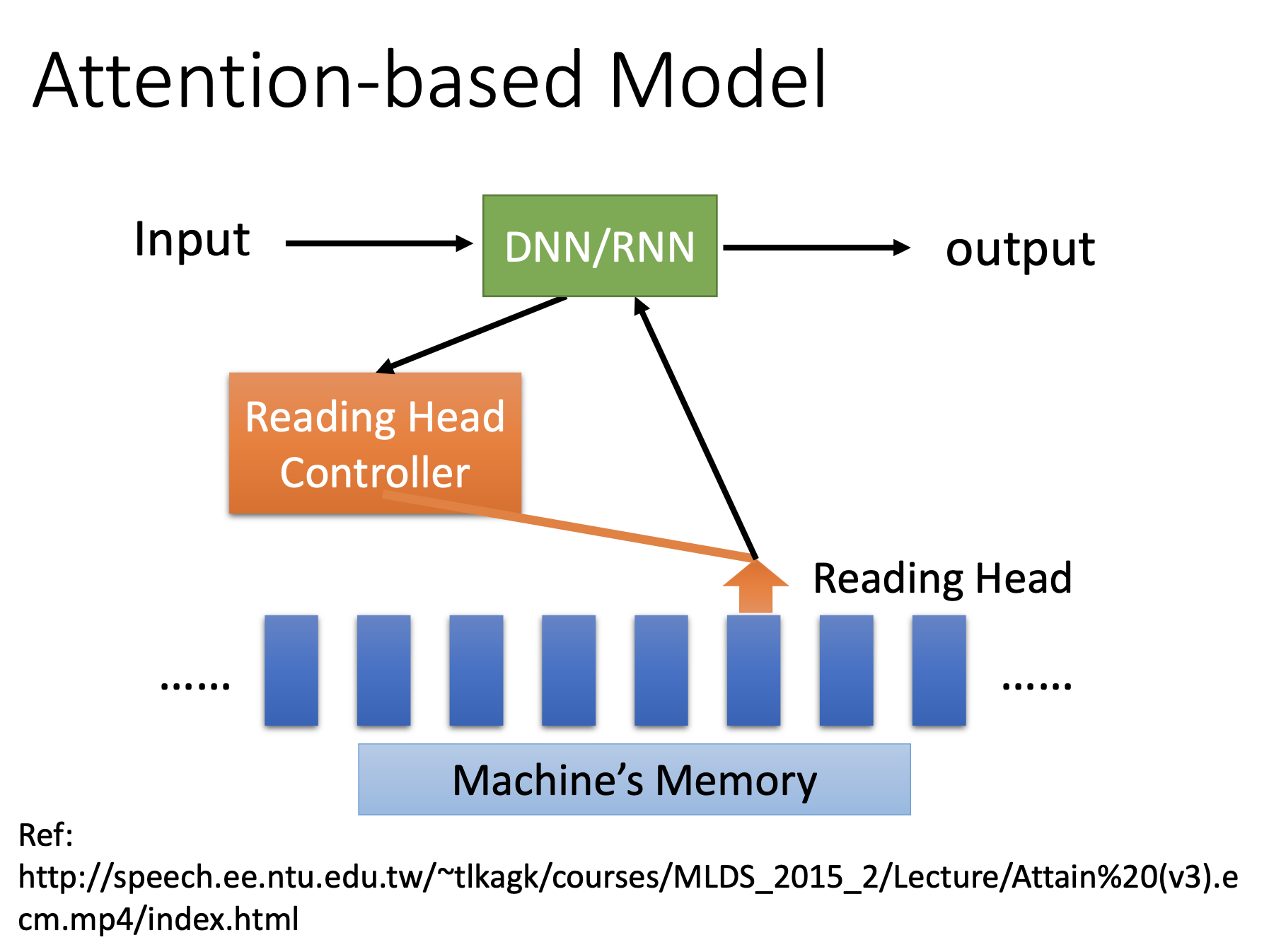
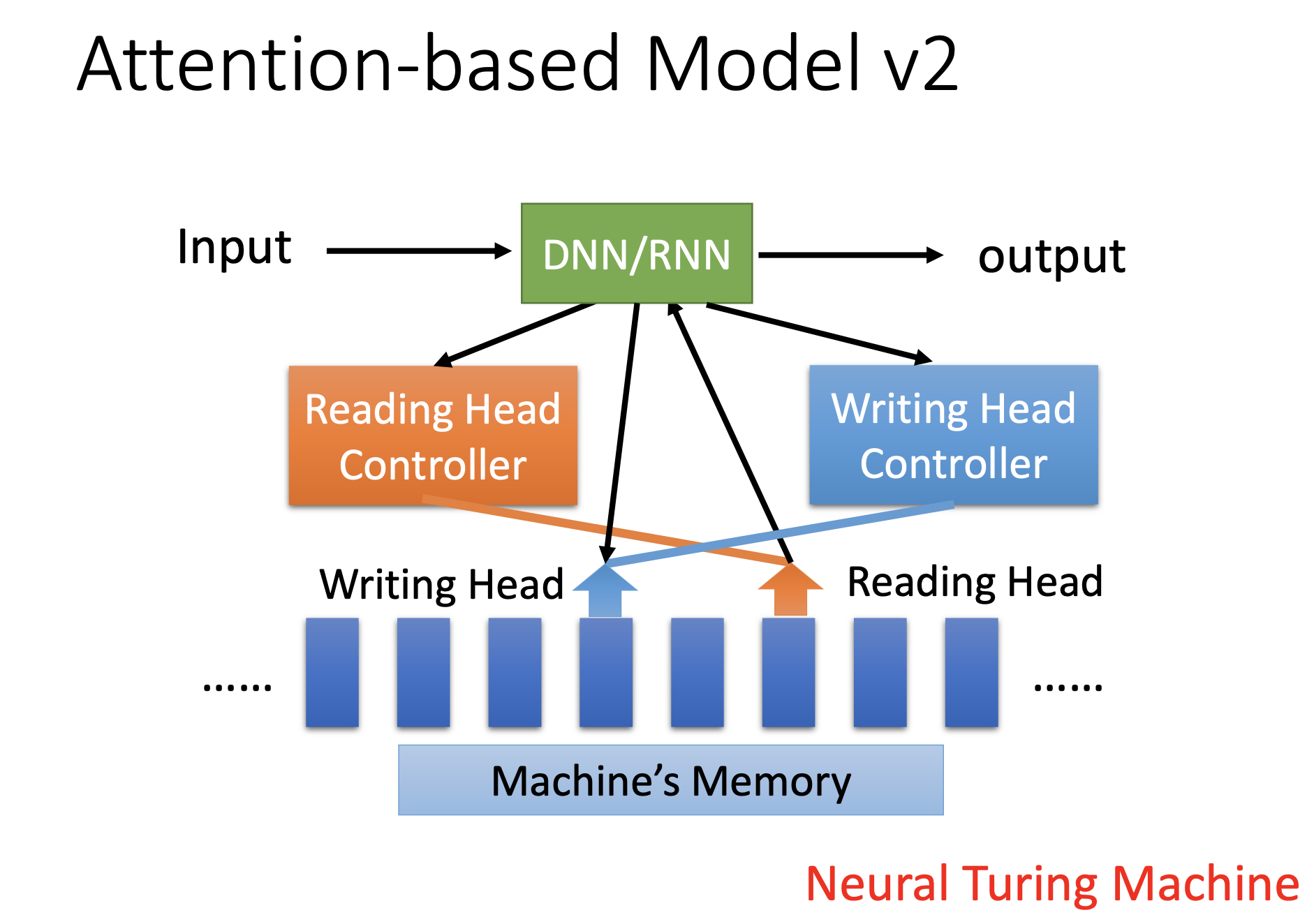
Attention Based Model
Concepts
Reading Comprehension
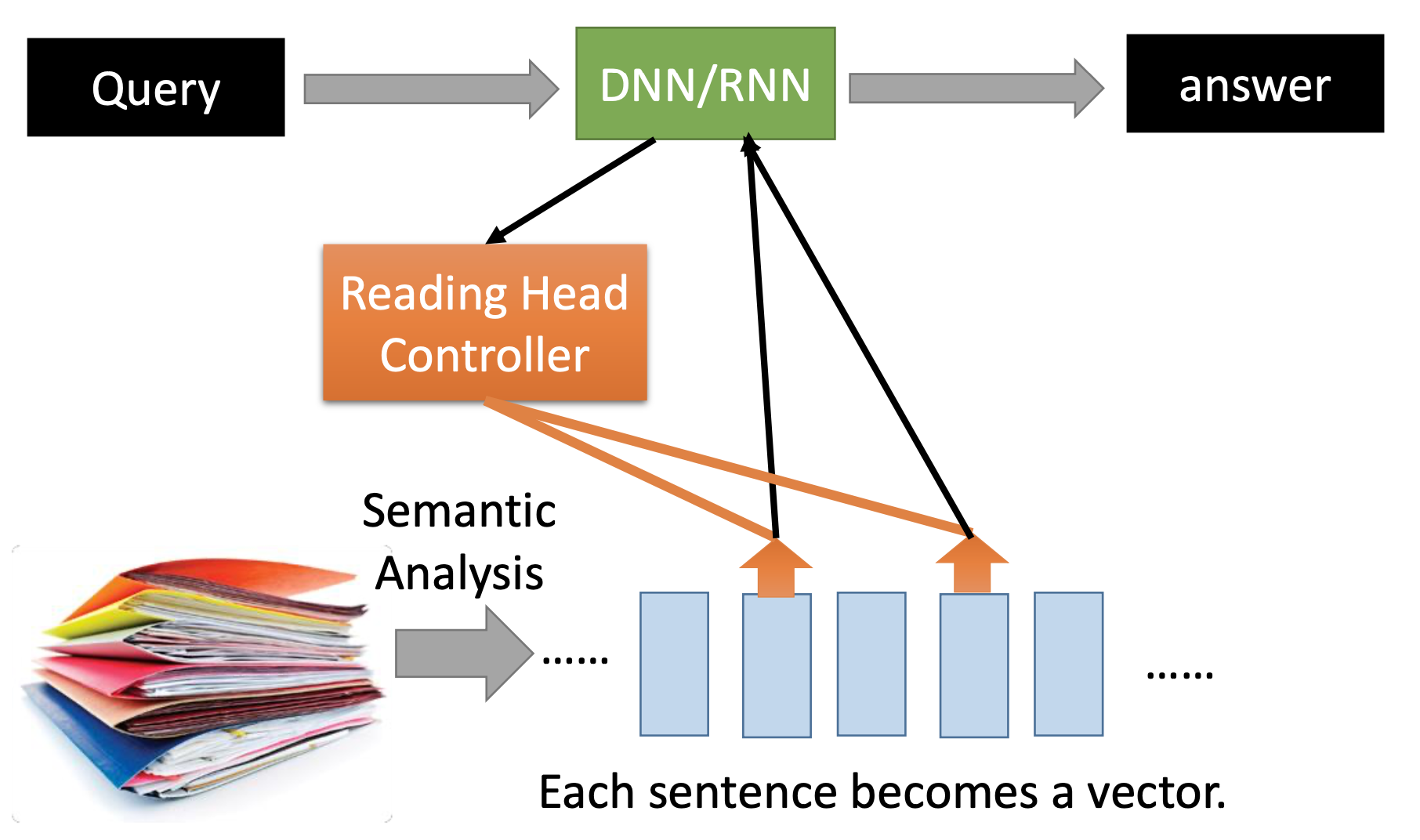
ref: End-To-End Memory Networks. S. Sukhbaatar, A. Szlam, J. Weston, R. Fergus. NIPS, 2015. Keras example
Visual QA
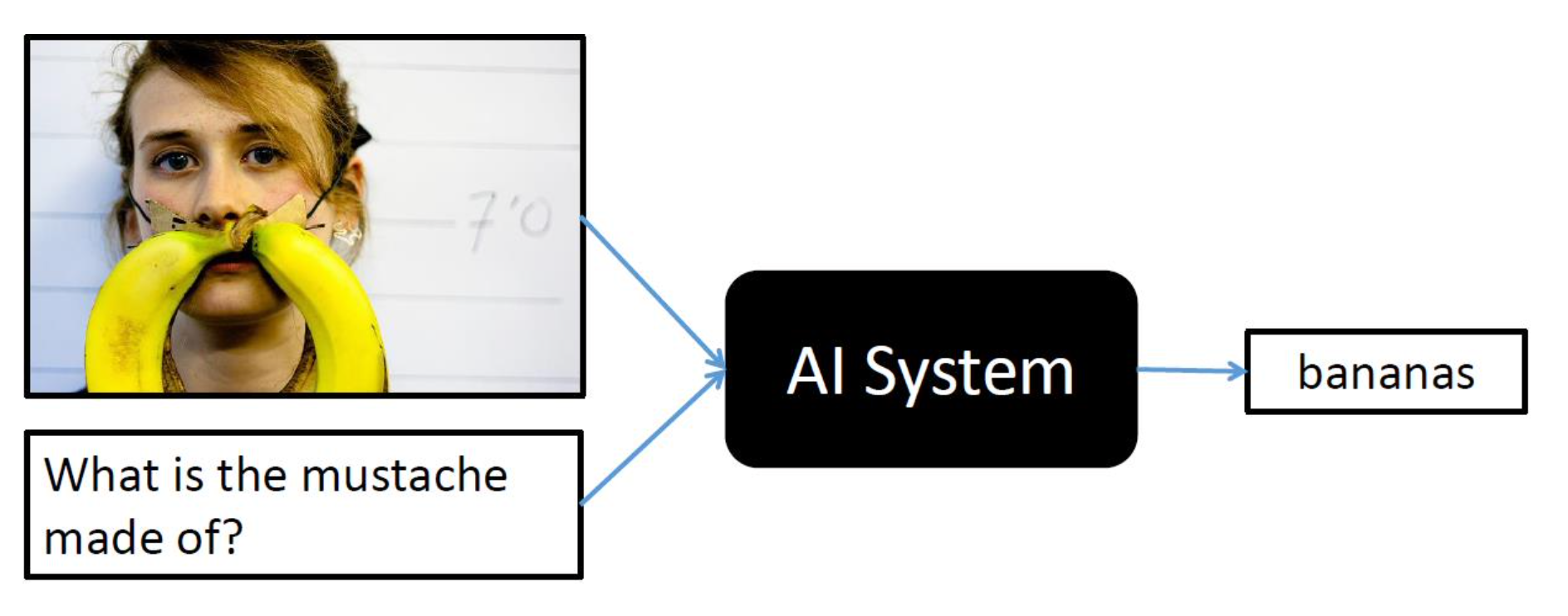
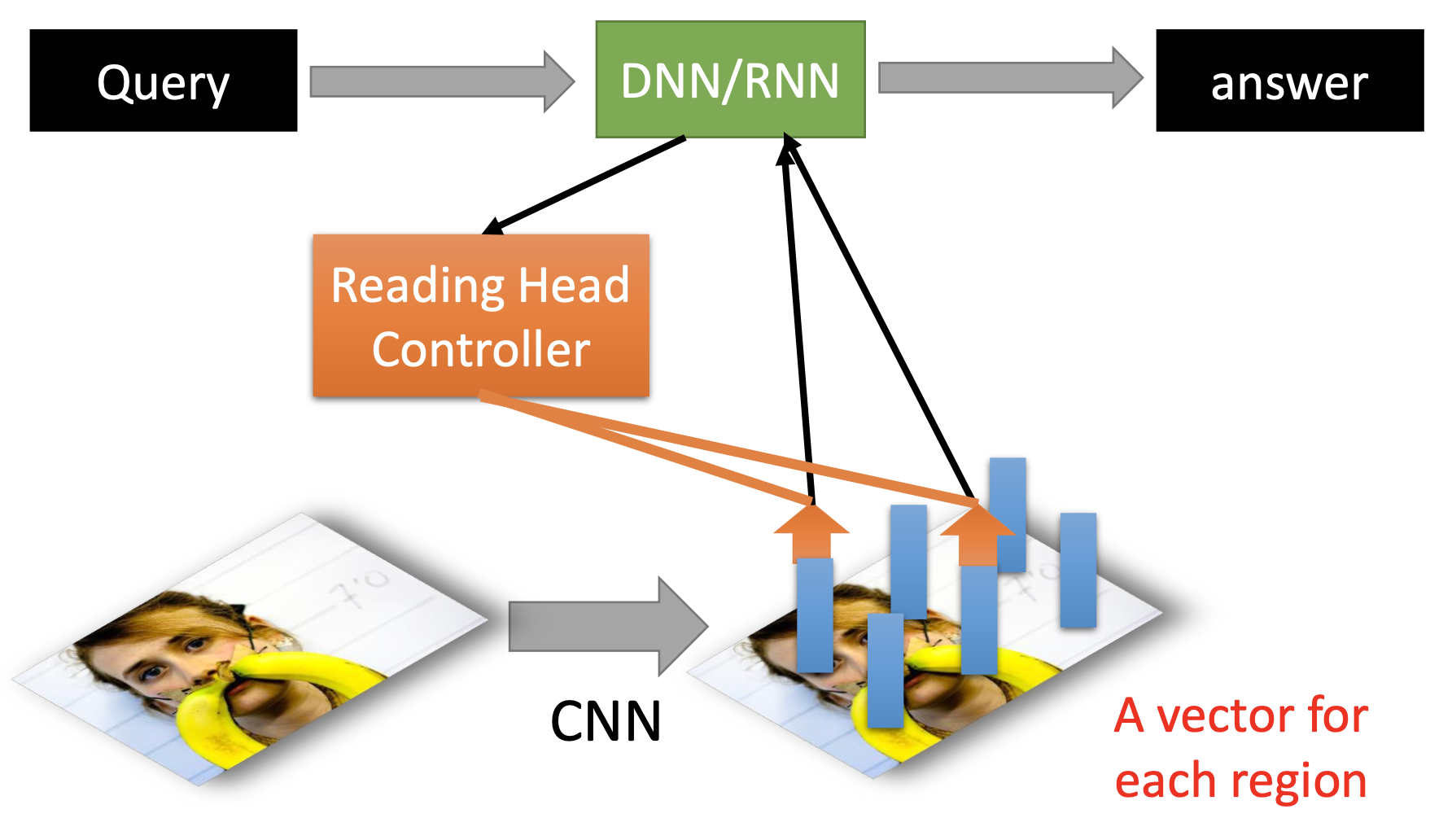
Speech Question Answering.

The future direction may be the combination of the structured learning and DNN.
We can also seen GAN as a kind of structured learning.
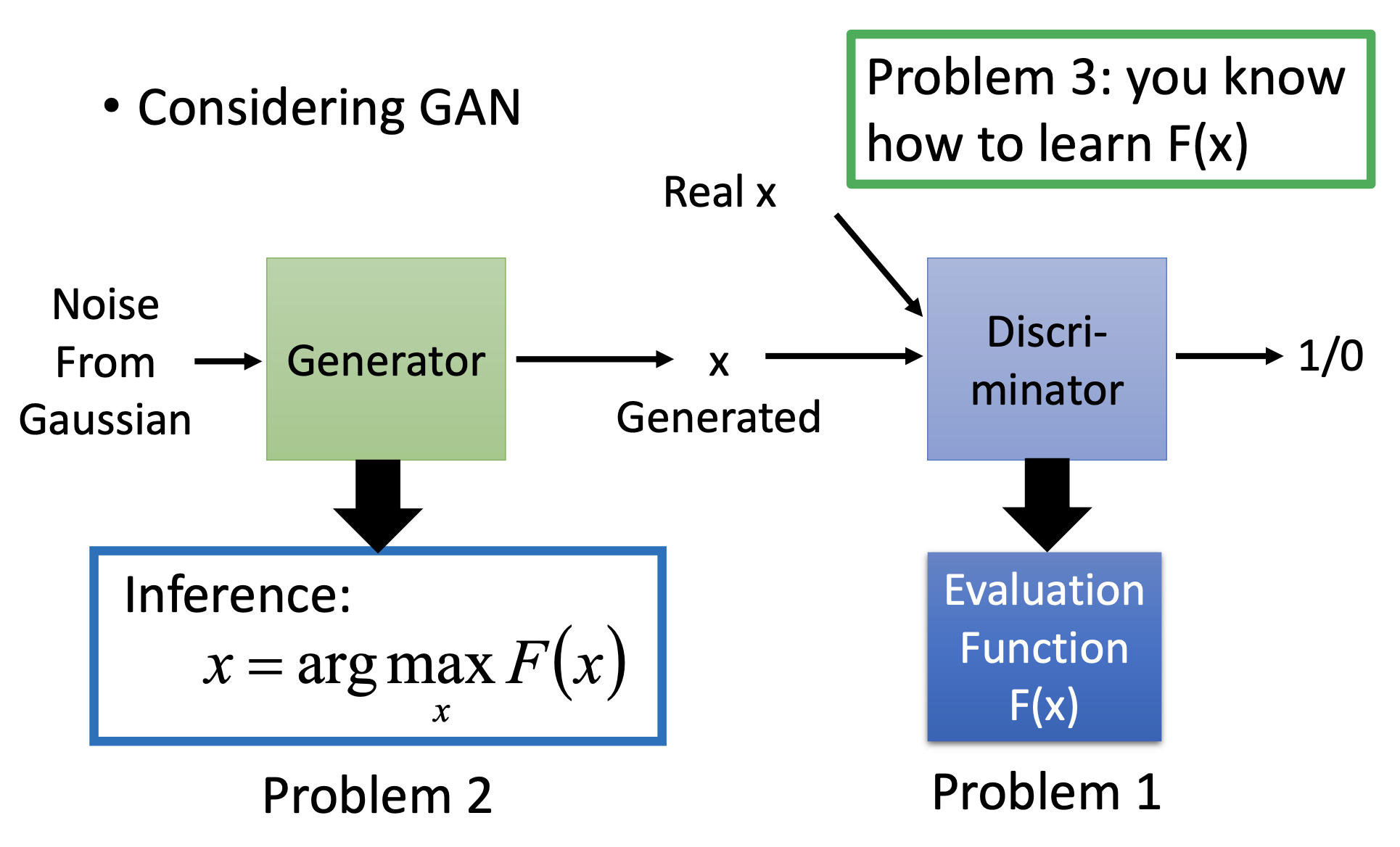
RNN vs Structured Learning
References
Youtube ML Lecture 21-1: Recurrent Neural Network (Part I)