Notes for Prof. Hung-Yi Lee's ML Lecture: Transfer Learning
Transfer learning is about the scenarios that we have data which are not directly directly related to the task considered. Besiedes, the usage of terminologies in the field of transfer learning are somewhat chaotic, so the meaning of some terms may vary between articles.
Categories of Transfer Learning
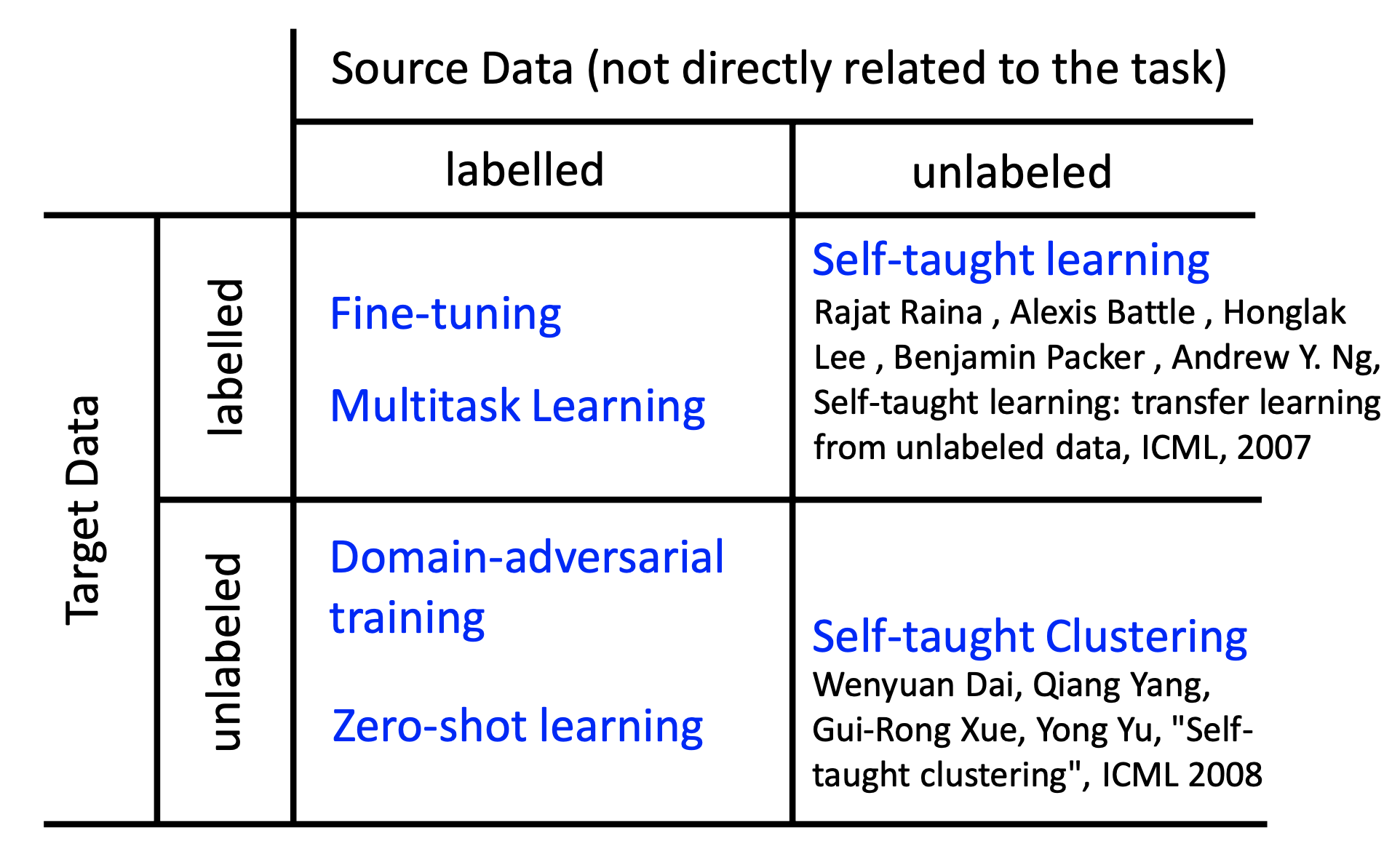
Model Fine-Tuning
We have a large amount of source data and very little target data, both are labbelled. We train the a model by the source data first and then re-train it by the target data. The challenge is that we have only limited target data, so be careful about overfitting. We have the following methods:
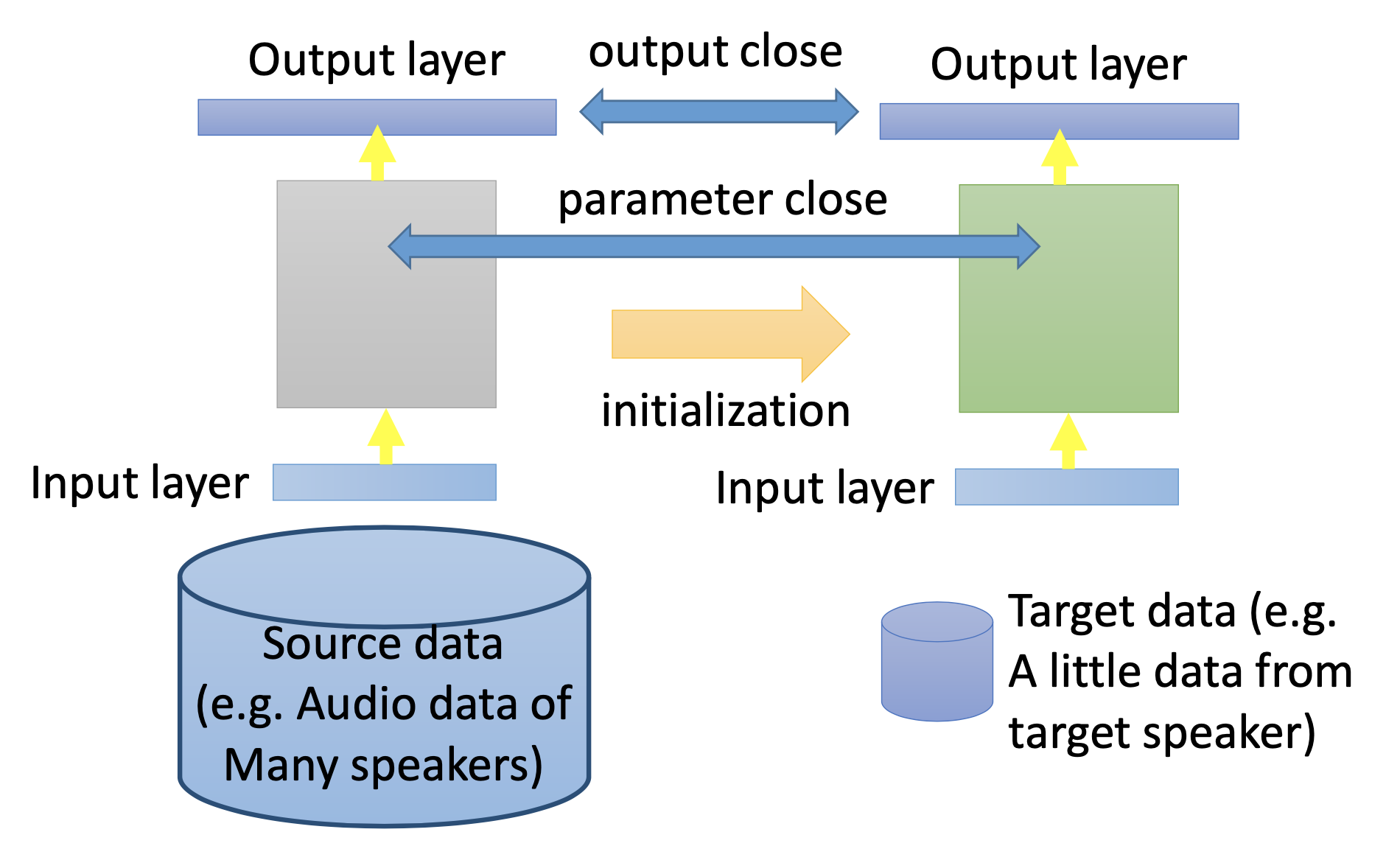
Conservertive Learning
Make constraints, i.e. regulatizations, to let some parts of the re-trained model to be close to the pre-trained model.
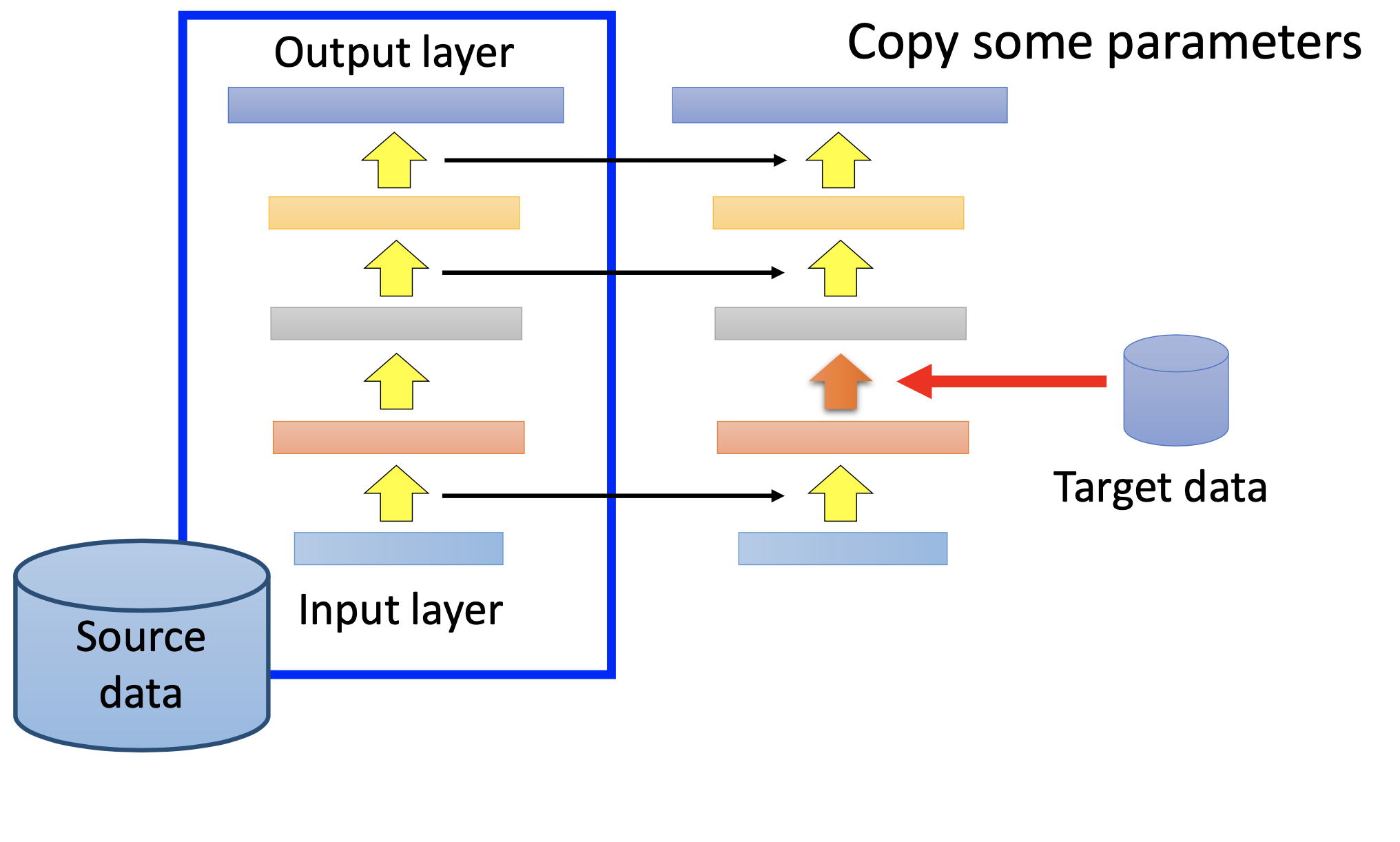
Layer Transfer
When training by the target data, we copy some layers of the pre-trained network, while the others are randomly initialized. If we have very limited data, then we fix the transfered layers and train only the others; if we have sufficient data, then we fine-tune the whole network.
Which layers to be transfered dependes on the task. For example, for image recognition, usually we fine-tune the last layers because the former layers are for extracting pattenrs fram the images; for speech recognition, ususally we fine-tune the first layers because the parameters for extracting patterns varies to fit the unique vocal mechanisms of individuals.
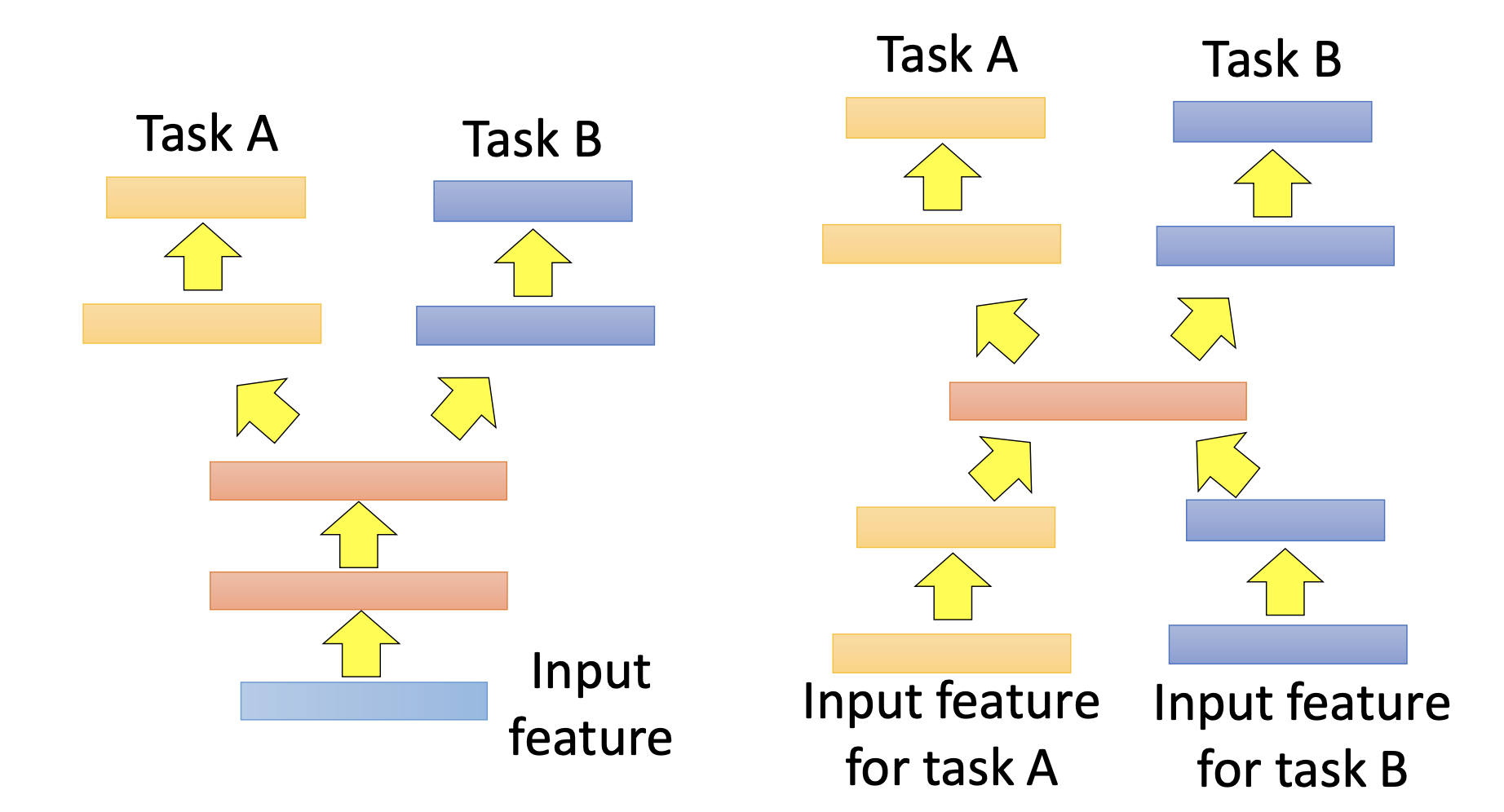
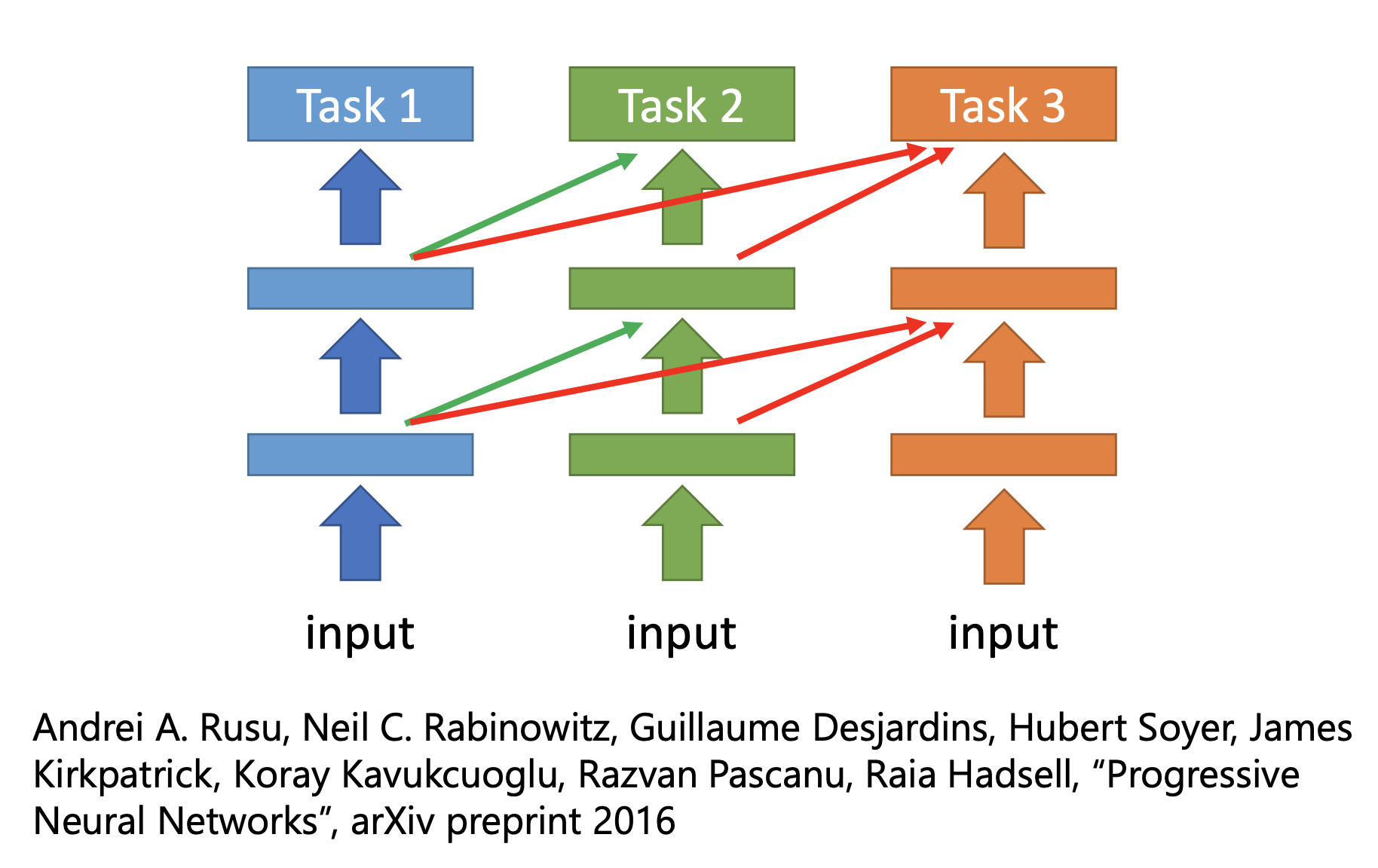
Multi-Task Learning
We have a labelled source data and target data. We want the network to have better performance by the source data.
We let multiple networks share some layers.
To let the network learn which layers to be shared, there’s Progressive Neural Networks.
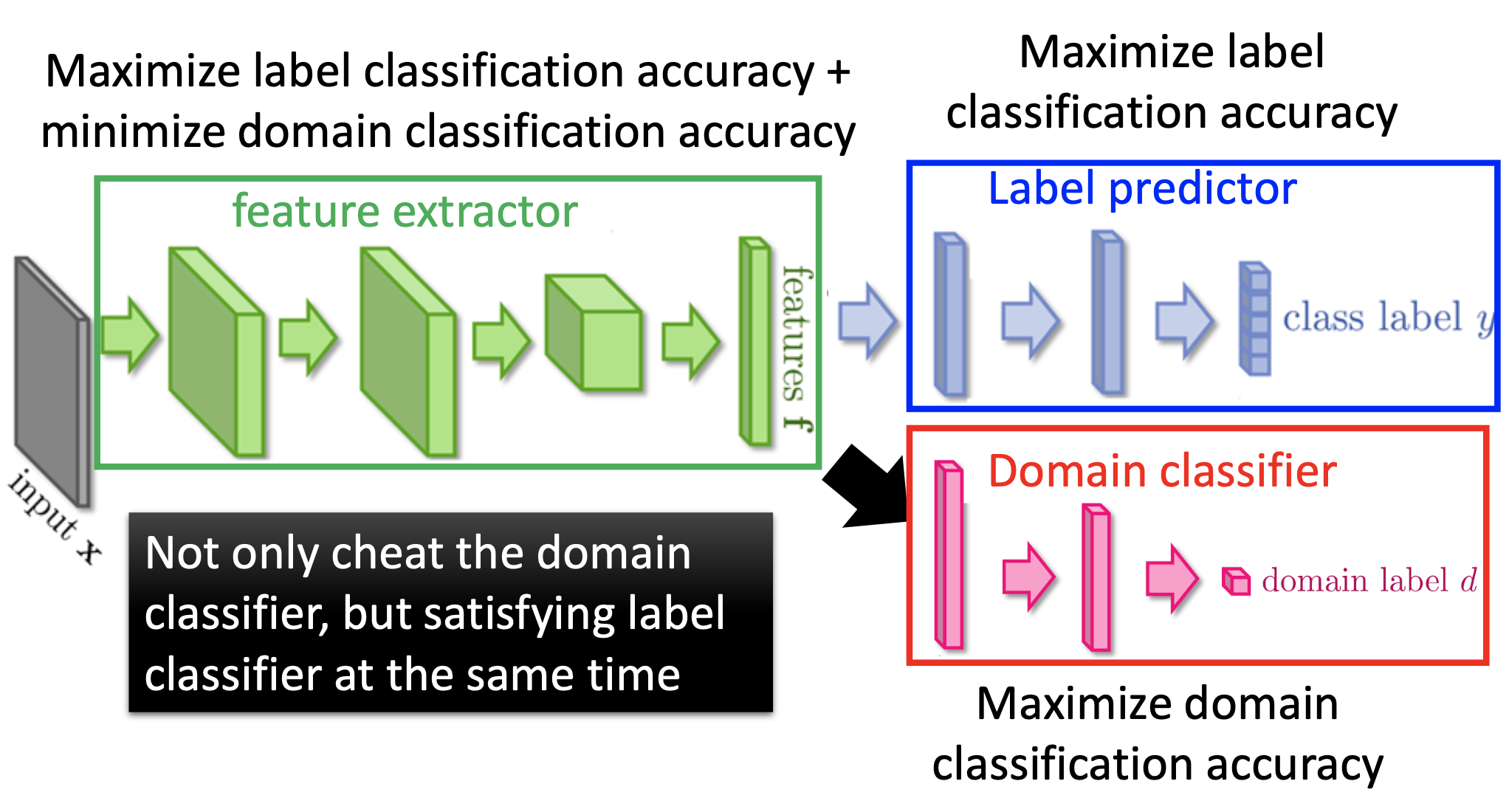
Domain-Adversarial Training
We have labelled source data and unlabelled target data. We want to make a network that can classify the target data. We make a network that are composed of a feature extractor, a label predictor, and a domain classifier. The label predictor maximize the label classification accuracy on the source data; the domain classifier maximize domain (i.e. source or target data) classification accuracy; the feature maximize the label classification accuracy and minimize the domain classification accuracy. As a consequence, the feature extractor will remove the domain related information at its output to fool the domain classifier. The training can be realized by a gradient reversal from the domain extractor to the feature extractor.
Zero-Shot Learning
We have labelled source data and unlabelled target data. The target data is unlabelled, so it’s “zero-shot”.
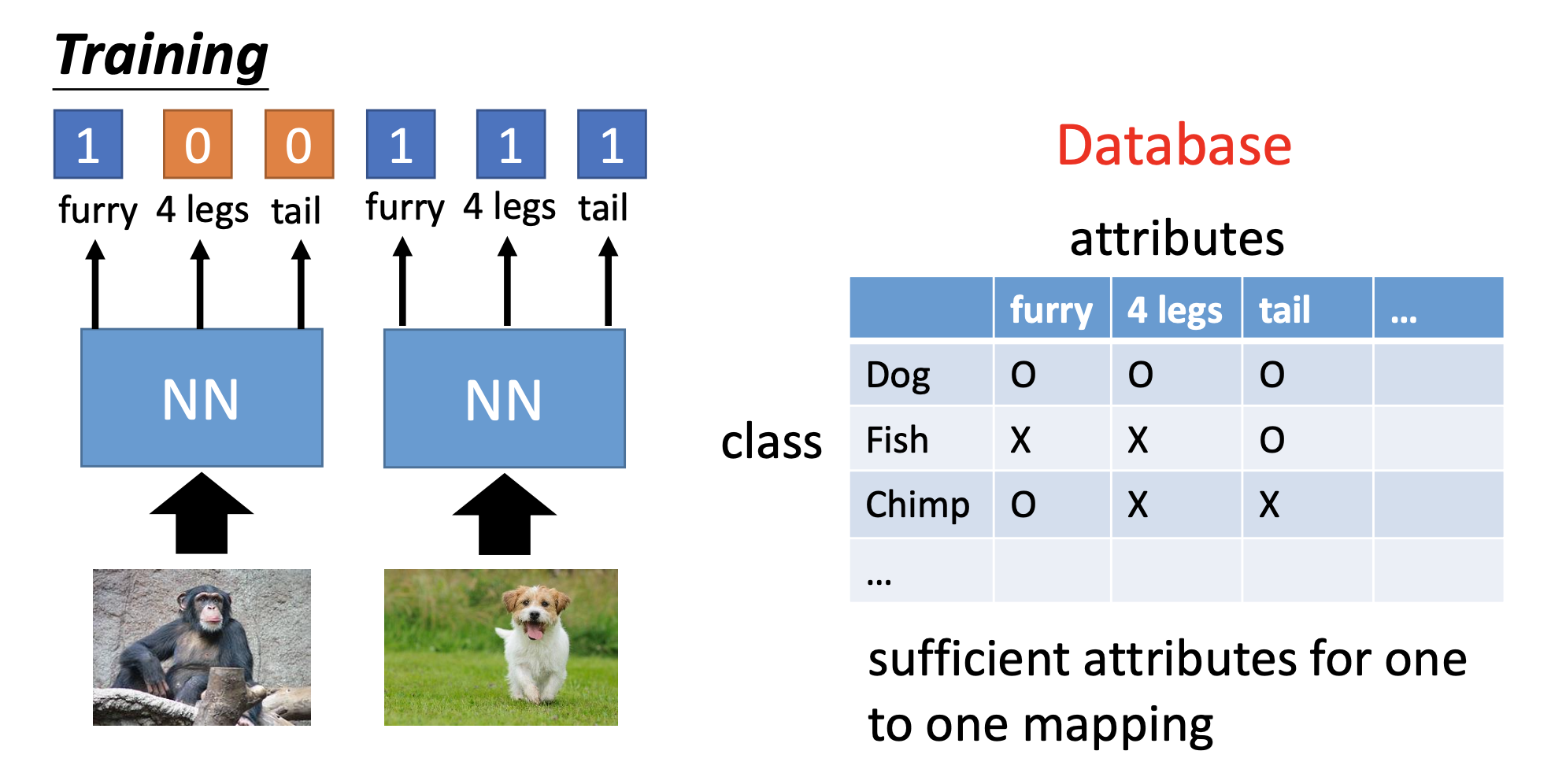
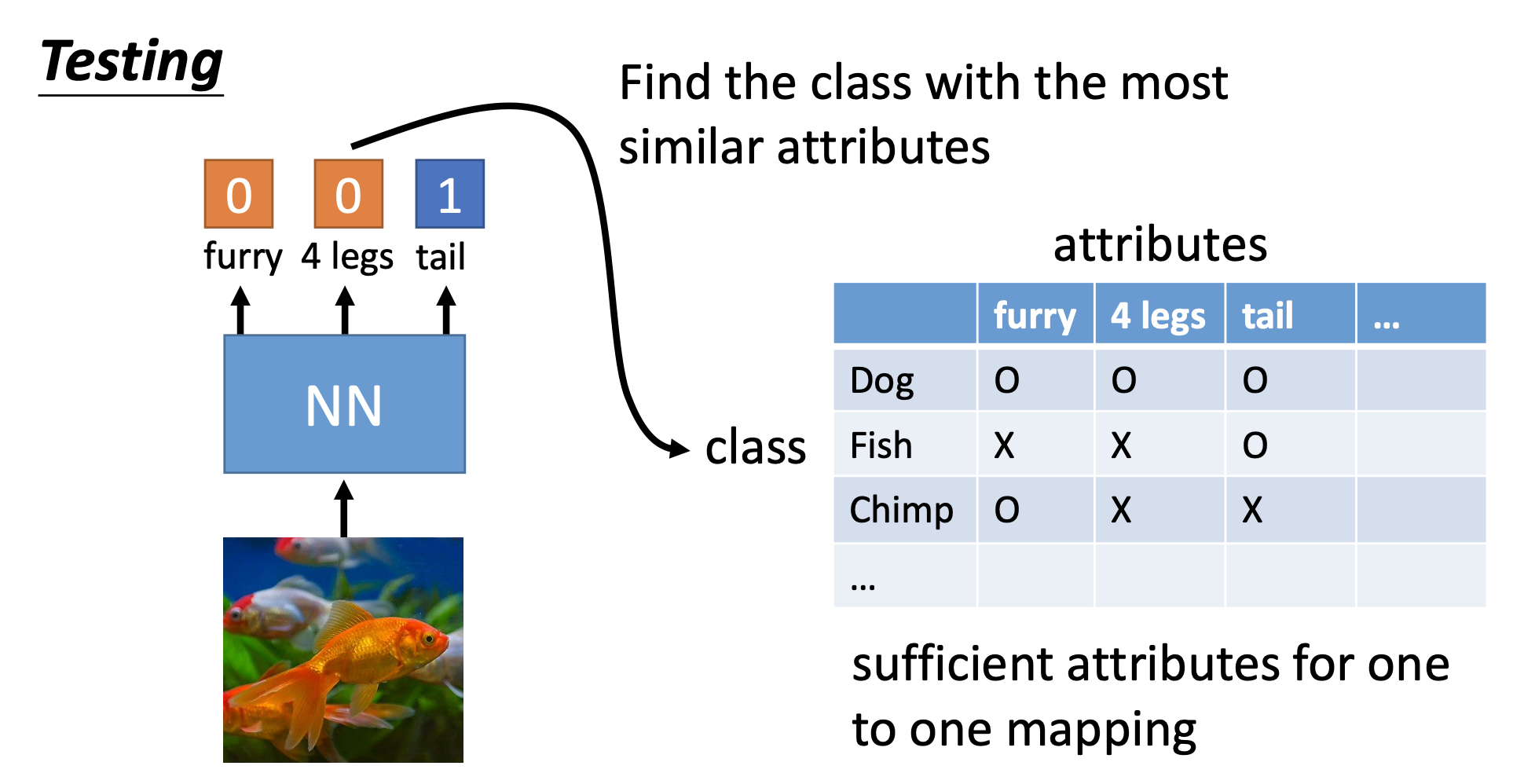
Train by Attributes
We make a table that map the classes to attributes. Then we train a network by the source data to produce attributes from the inputs. Finally, we use the trained network to generate attributes for the target data to perform classification.
Attribute Embedding
We train functions $f$ and $g$ to transform the original data and the attributes into a high-dimensional space and that those from the same pair be close to each other. If we don’t have the attributes data, we can just use word embedding. Finally, we can apply the functions on the target data and let the closest class be the result of classification.
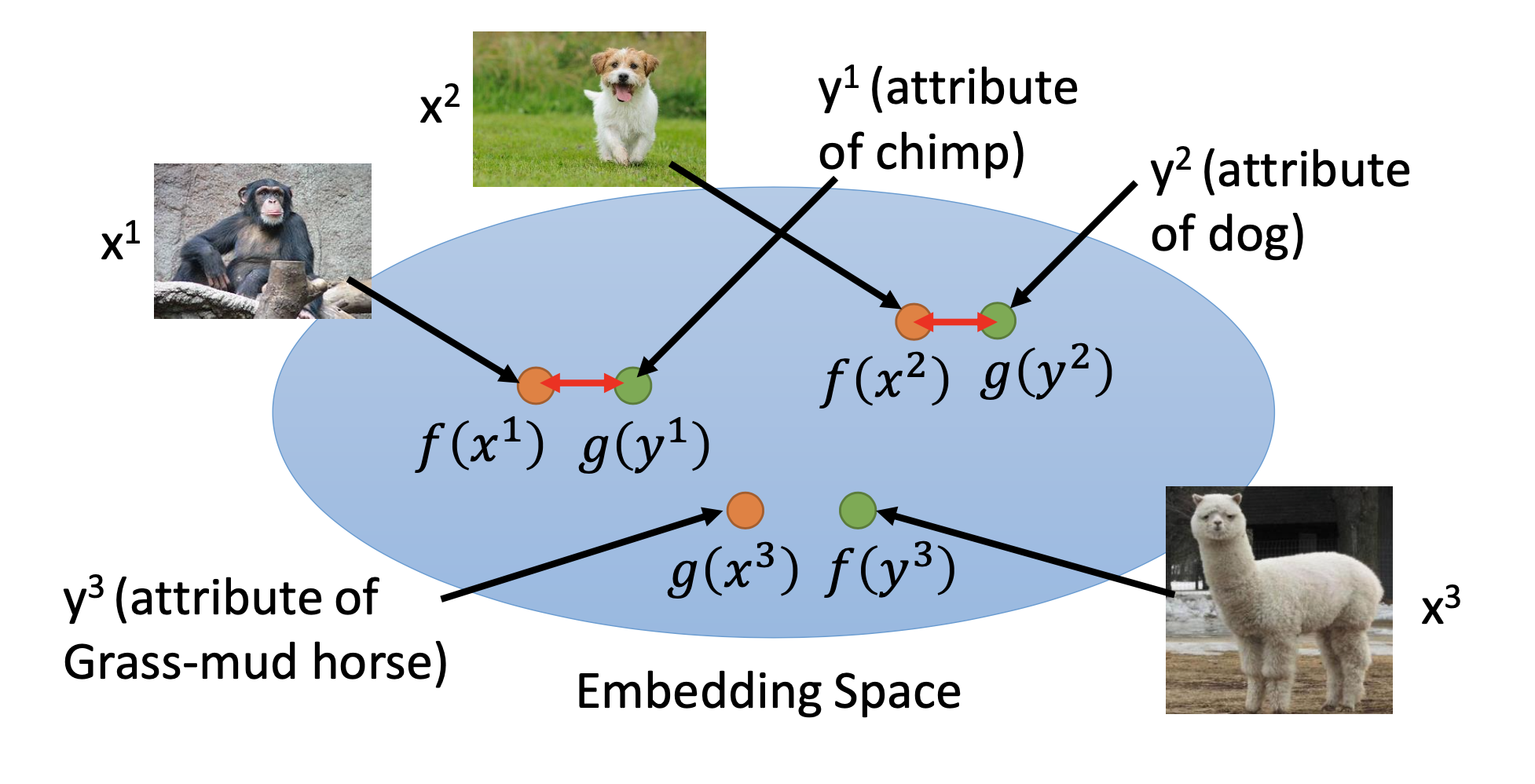
To avoid finding trivial solutions for the network, we should optimize the $f$ and $g$ by the loss function:
\[f^*,g^* = arg \min\limits_{f,g}\sum_{n} max (0, k - f(x^n) \cdot g(y^n) + \max\limits_{m \neq n} f(x^n) \cdot g(y^m))\]Convex Combination of Semantic Embedding
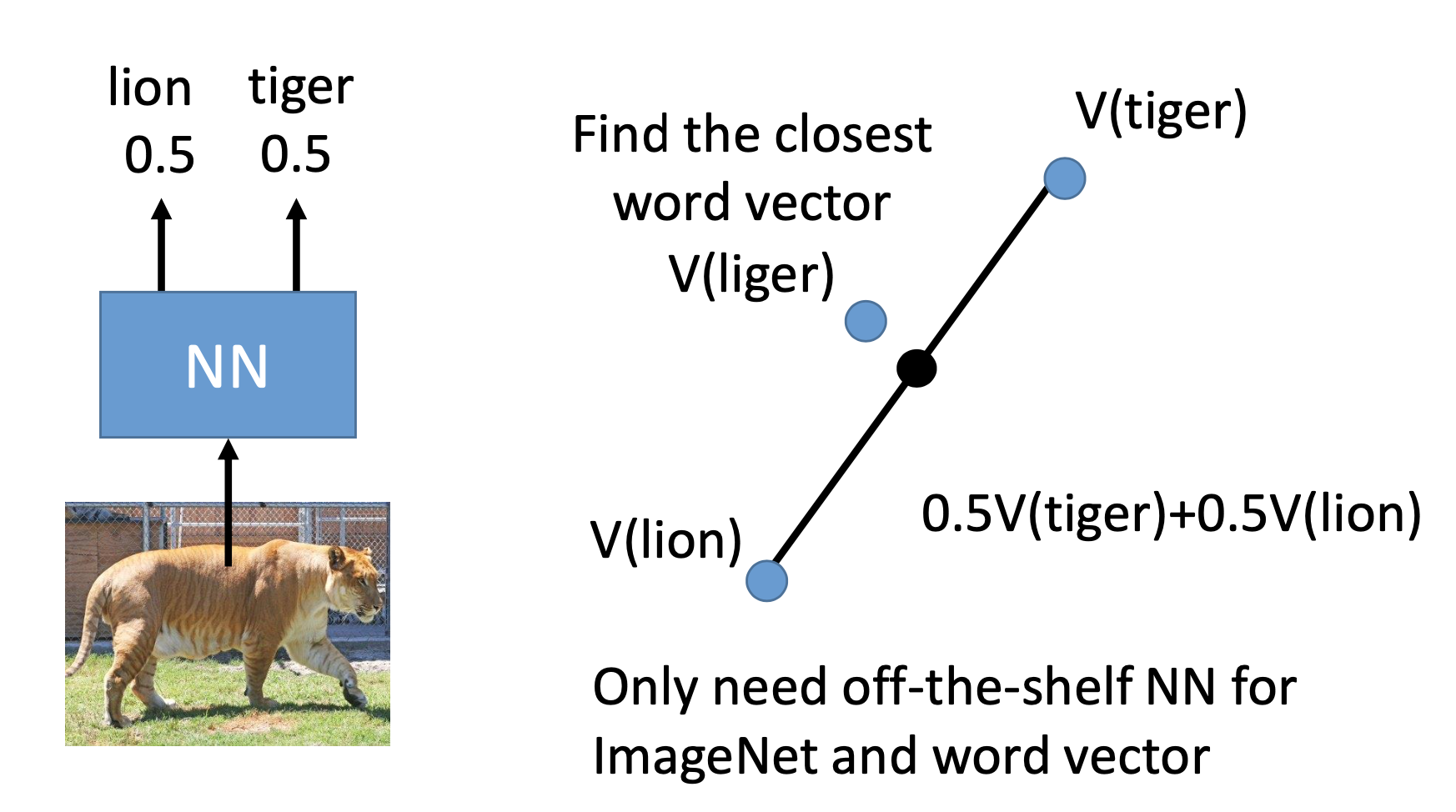
Find an off-the-shelf NN classifier, let it classify a target data, use the probabilities of the output classes on the corresponding word vectors to produce a new vector, and use the closest word as the result.
My discussions
The difference between transfer learning and semi-supervised learning: in semi-supervised learning, we assume all data are related to the task.