Notes for Prof. Hung-Yi Lee's ML Lecture: More about Auto-Encoder
More than minimizing reconstruction error
“An embedding should represent the object”, this is the our motivation to make the embeddings. By such concept, we have the question “how to evaluate an encoder”. By following the question, we have other approachs to train the encoders, i.e. to train the encoder by the discriminator
Deep InfoMax
We build an encoder that generate a code by an input object, while this time we build a discriminator that take an input object and a code as its input, and recognize whether the code comes from the object. The encoder has parameters $\theta$ and the discriminator has parameters $\phi$. Let the loss of the diecriminator be $L_D$, then for the discriminator, we train $\phi$ to find the minimum of $L_D^*$, i.e.
\[L_D^* = \min\limits_{\phi} L_D\]and for the encoder, the lower the $ L_D^* $, the better the representations, so we train $ \theta $ to find the minimum of $ L_D^* $, then
\[\theta^* = arg \min\limits_{\theta} L_D^* \\ = arg \min\limits_{\theta} \min\limits_{\phi} L_D\]we train the encoder and the discriminator simultaneously to minimize $L_D$. This is the Deep InfoMax (DIM).
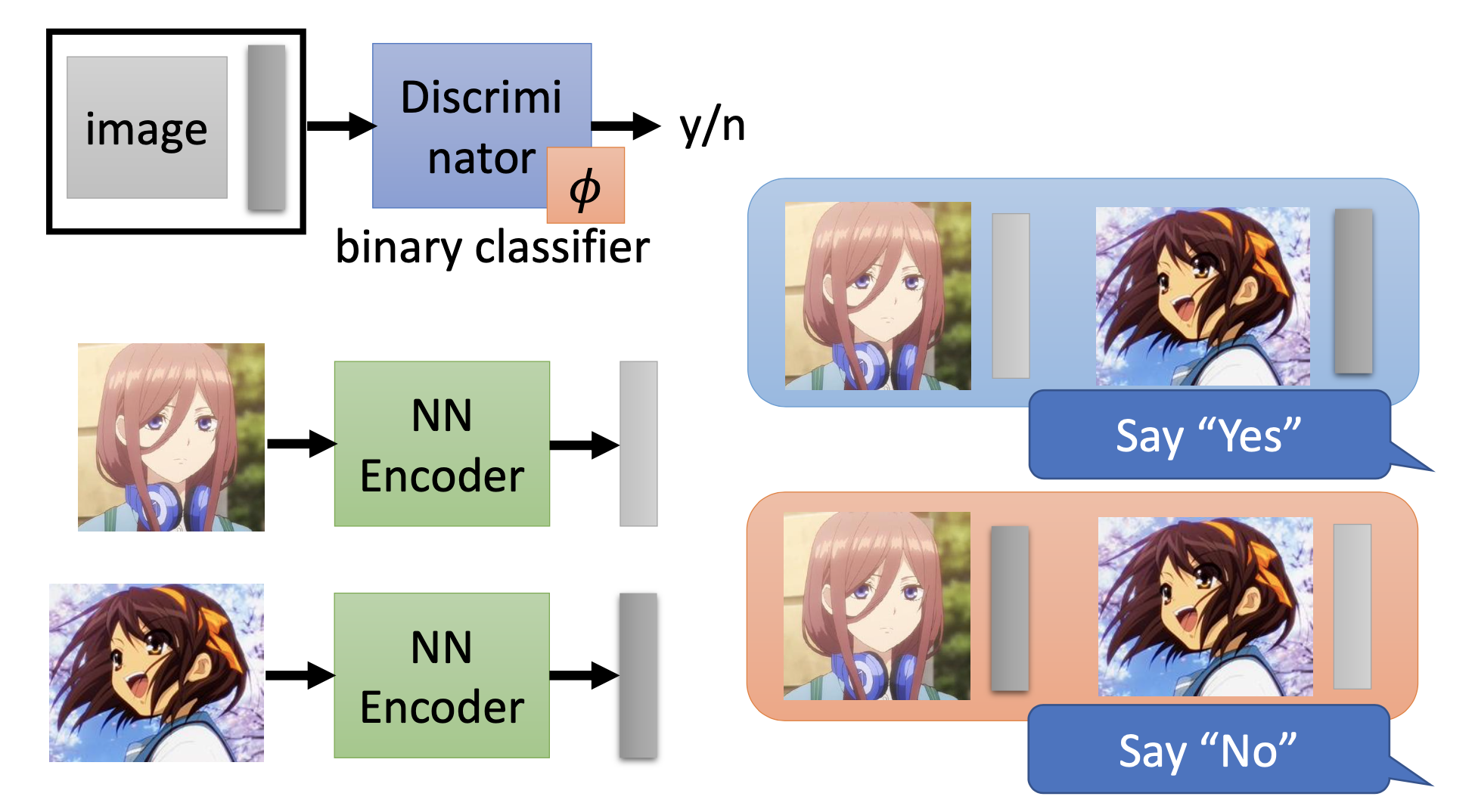
Besides, we can see the typical auto-encoder as a special case of the encoder-discriminator approach. We can simply use the reconstruction error of the typical aotu-encoder as a score for the discriminator.
The encoder-discriminator approach also has some advantages. We don’t train an decoder, that saves computing cost. On the other hand, we have more data for the discriminator, i.e. we have both positive (the code comes from the object) and negative (the code doesn’t come from the object) examples. While for typical auto-encoder, we have only positive examples.
Quick Thought
For sequential data, there’s skip thought to generate the embeddings for the sentences. They use the current sentence as the input to generate the previous and the next sentence as output. And then there’s quick thought: instead of training a decoder to generate sentences, they train a classifier that take embeddings of sentences as input, including the current sentence, the next sentence, and some randomly found sentences, and recognize which one is the next sentence. Without training an decoder, the training become quicker.
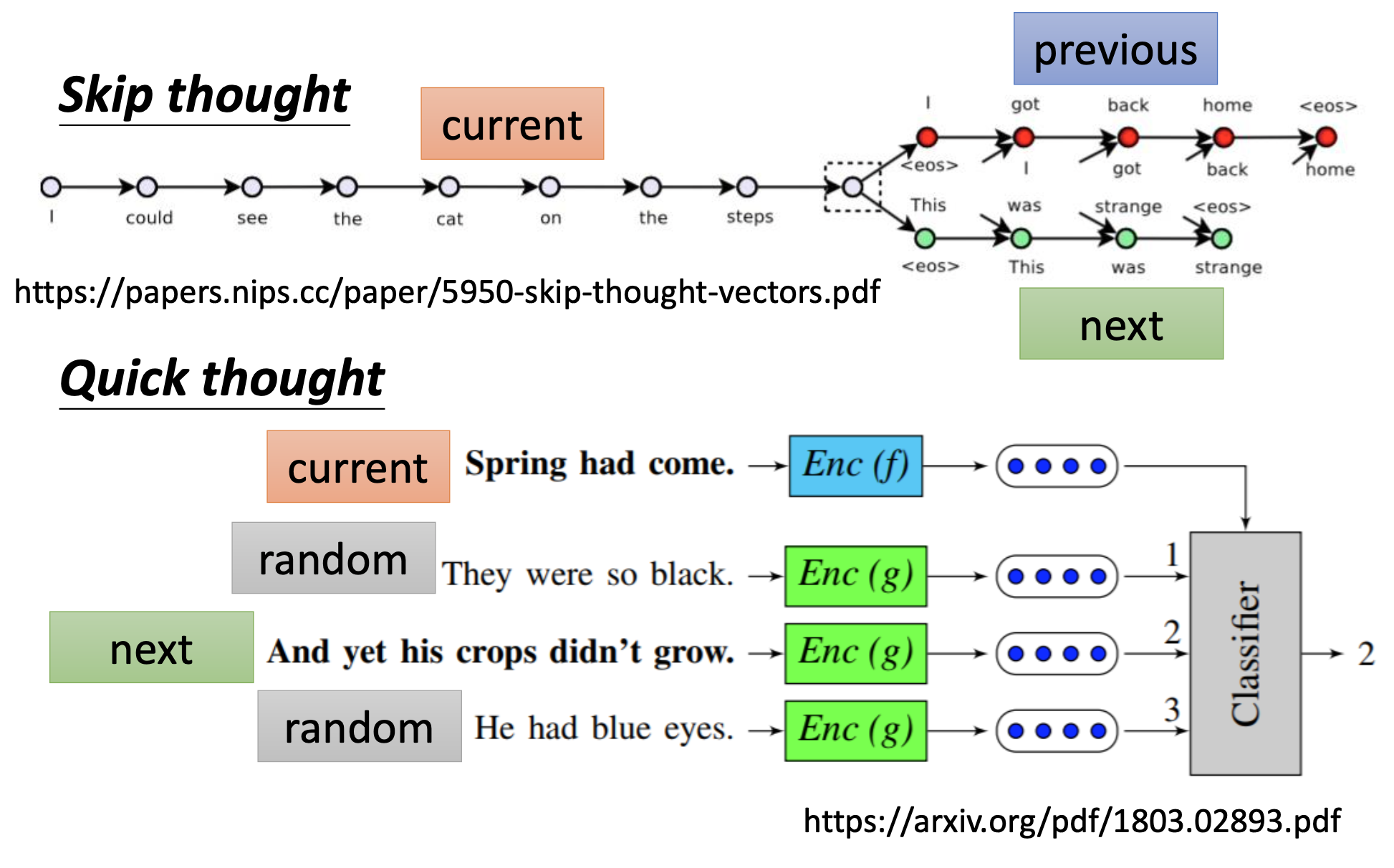
The classifier actually computes the inner product of the embeddings to recognize the next sentence. With the random sentences, the encoder has to let the embedding of the unrelated sentences be far from each other. If we simply design the task to let the embedding of the next sentence be close to the embedding of the current, the encoder may trivially transform every sentences to identical embedding.
Similarly, for ausio, there’s Contrastive Predictive Coding.
Caution for designing the tasks
When designing the training of encoders and discriminators, always design the task to make sure the encoder won’t succeed by making trivial transformations.
More interpretable embedding
Feature Disentangle
We may want the different dimensions of the embeddings represent the information of differnet aspect. Take audio for example,
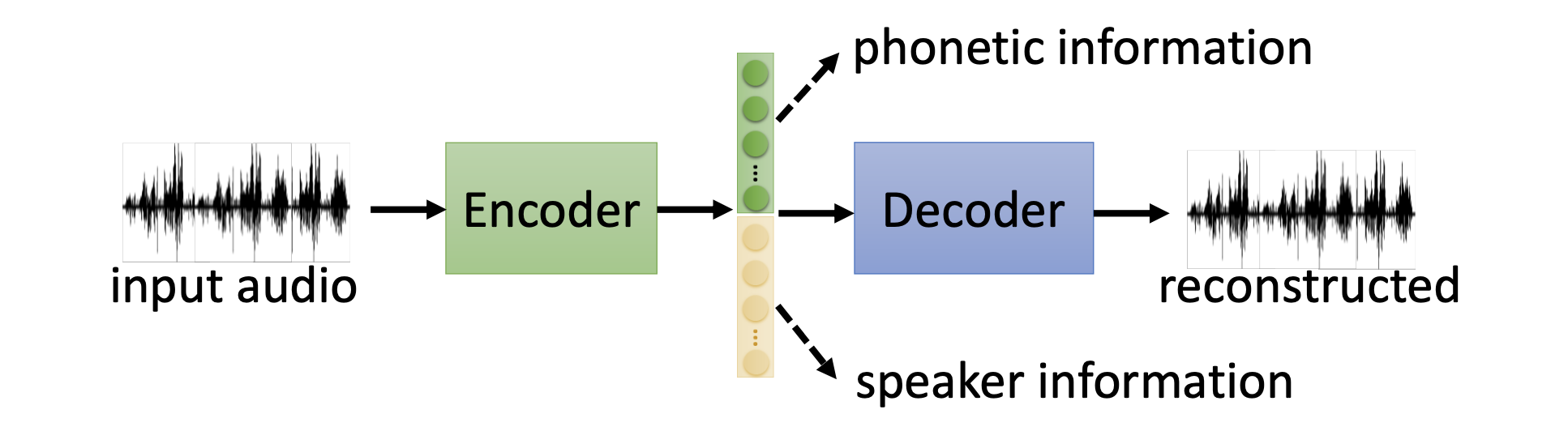
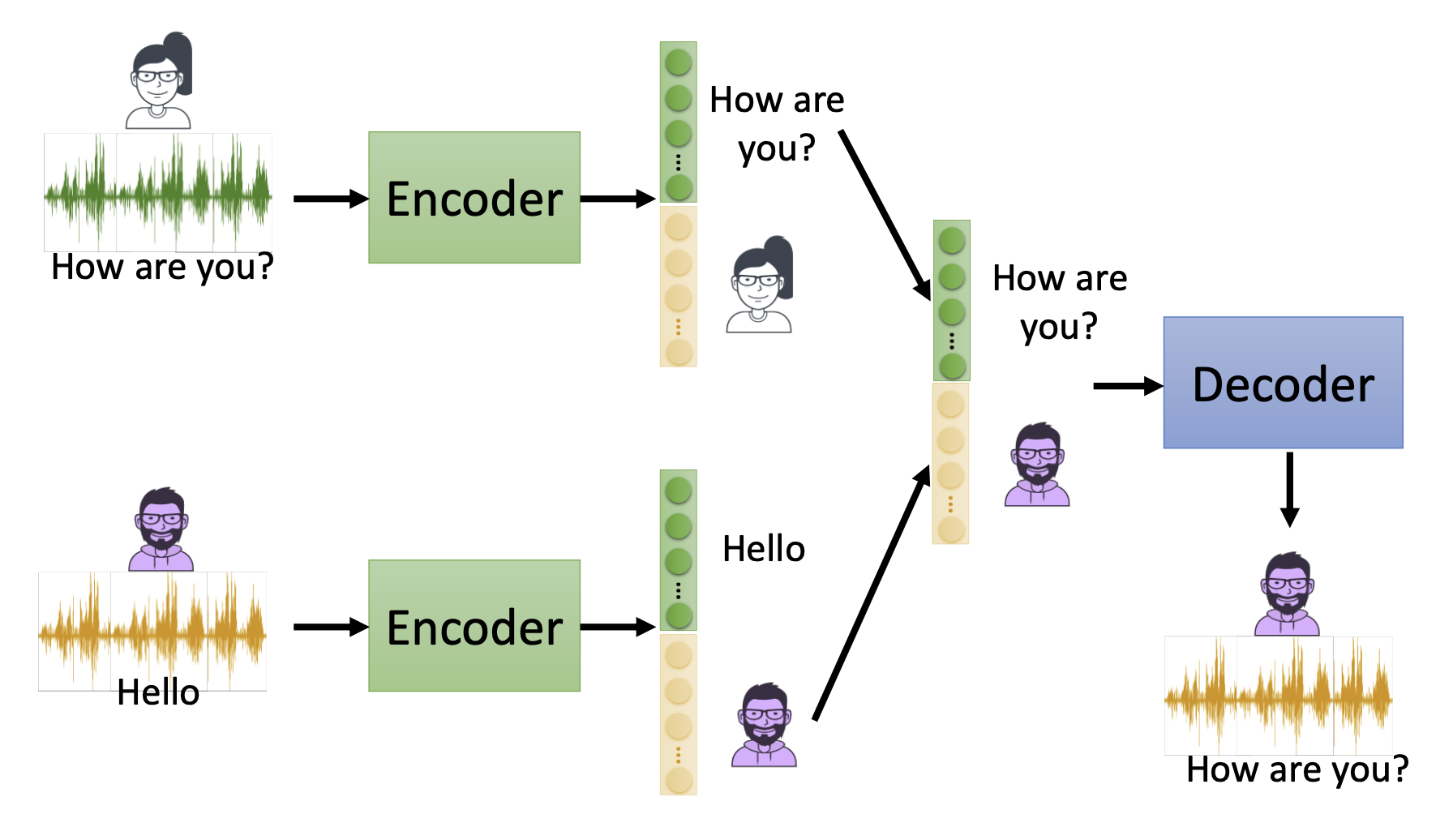
By such disentangle, we can perform voice conversion by using the embedding of phonetic information of a data and the embeddings of speaker information of another data
To achieve it, we make tricks on the architecture to let different parts of the embedding hvae only global or non-global information.
Discrete Representation
We may want the representation so that it’s easier to understand its meaning or just let it automatically be clustered.
One approach is to add a one-hot or binary layer right after generation of the code.
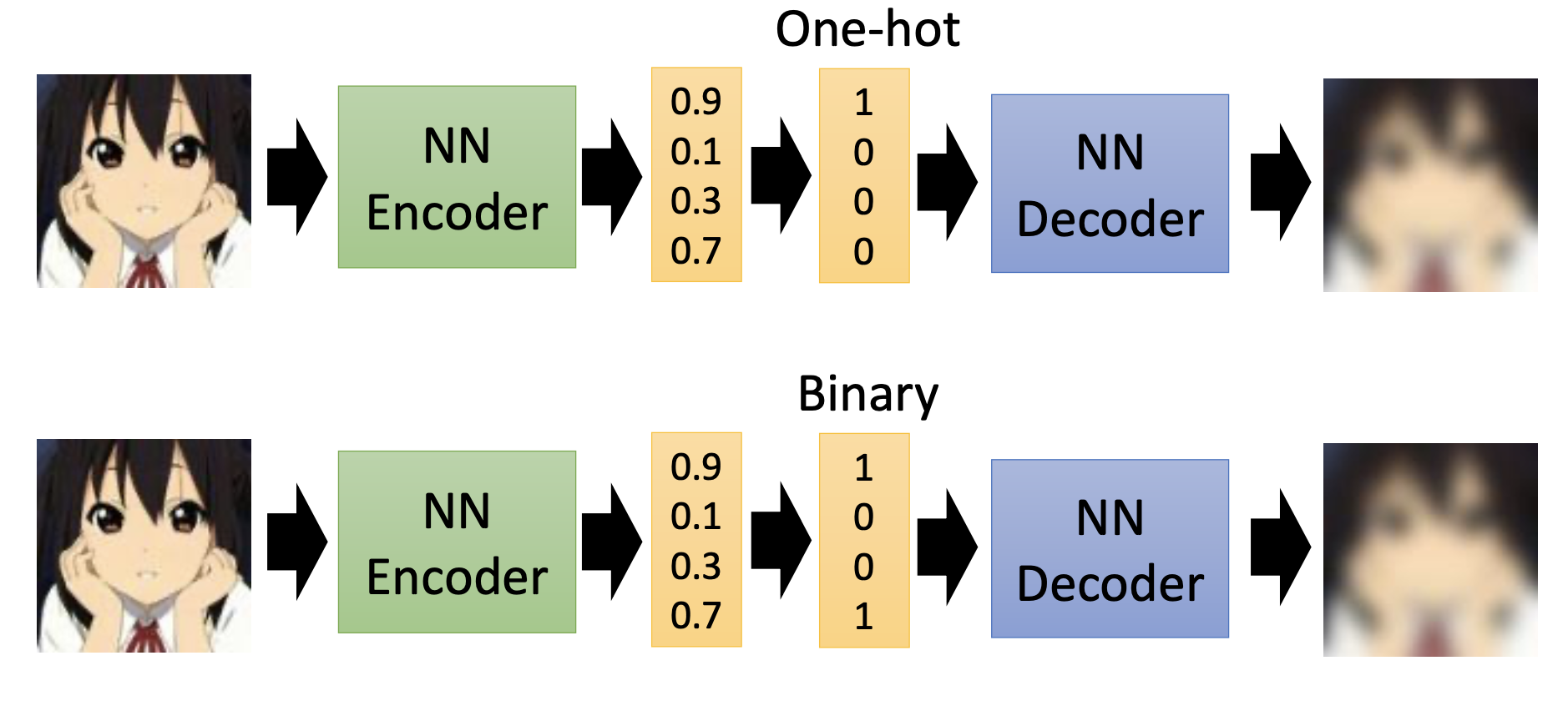
Binary representation may be better than the one-hot representation. The binary representation can represent the same total number of classes as the one-hot representation with less dimensions. Using the binary representation, it’s also possible to let the decoder generate instances that doesn’t exist in the training examplesby combinations of the bits.
VQVAE
Train a codebook simultaneously. We use the code in the codebook that is closest to the output of the encoder as the input to the decoder.
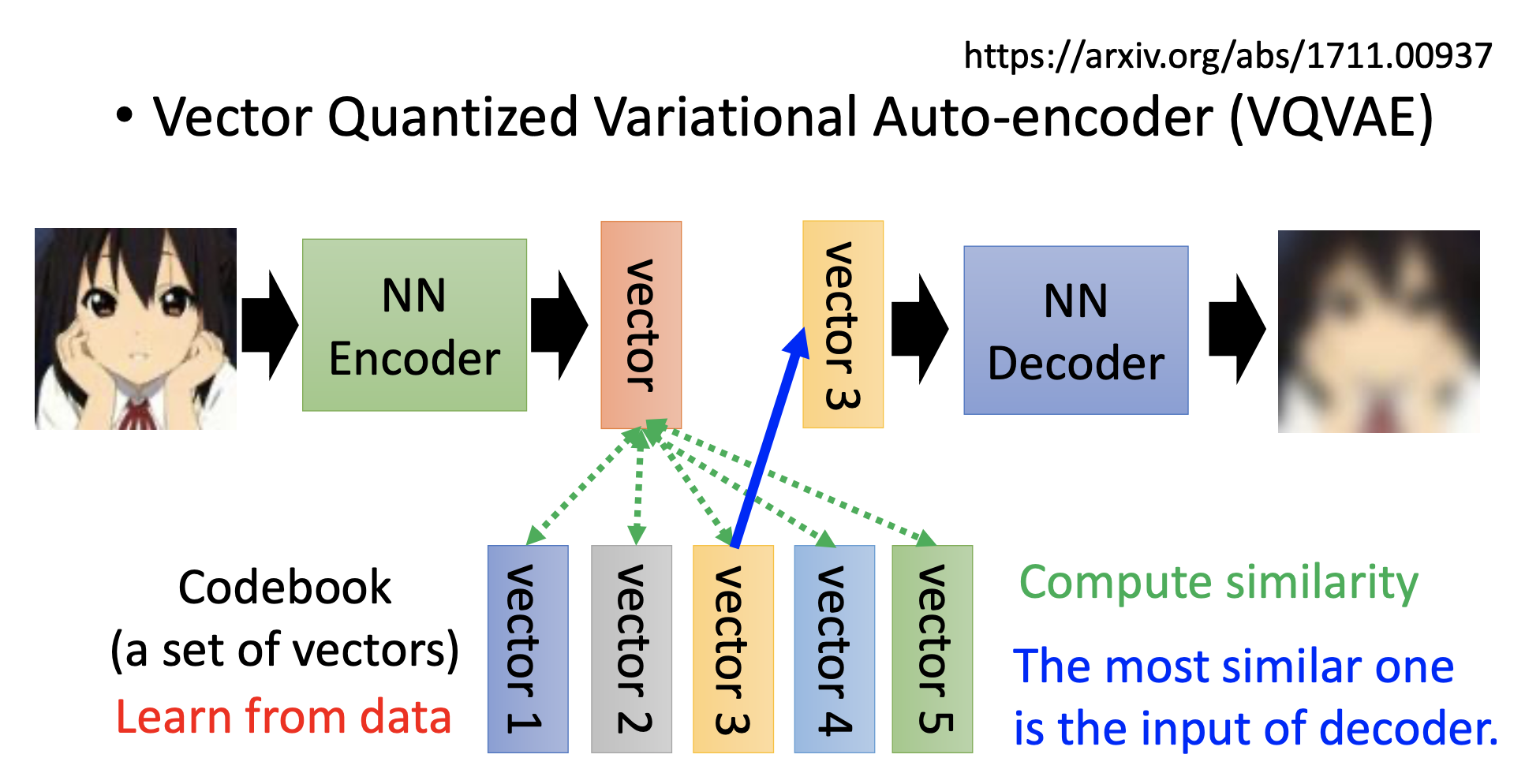
For speech, the codebook represents phonetic or semantic information.reference
Sequence as Embedding
Let the embedding be human-redable texts. This is a seq2seq2seq auto-encoder. Besides, since both the encoder and the encoder are machines, the code sequence may still be some texts which are unreadable for human, so we have to simultaneously train a discriminator that take the code sequence and another sequence written by human as input and recognize which one is written by human.
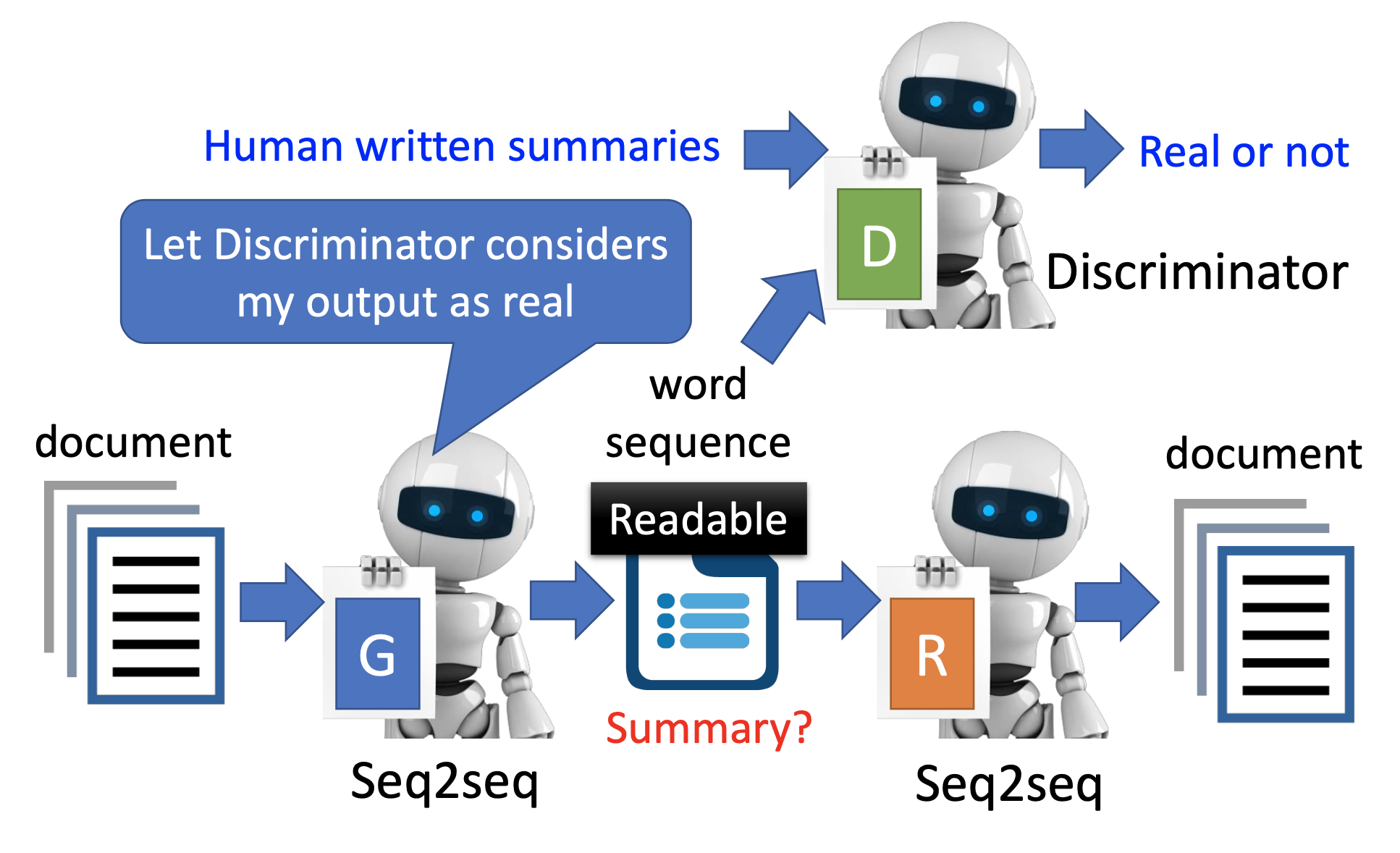
Similarly, we can also make trees as embedding. ref1 ref2
How to train network with non-differentiable layers
Or simply use reinforcement learning: loss funcion as reward, network as agent.
References
Youtube More about Auto-encoder (1/4)
Youtube More about Auto-encoder (2/4)
Youtube More about Auto-encoder (3/4)