Notes for Prof. Hung-Yi Lee's ML Lecture 16: Auto-Encoder
By the concept of auto-encoder, we train an NN encoder and an NN decoder simultaneously. The encoder is a function that generate a code by the input, and the decoder is a function that generate an output by a code. We also call the code as the embedding, the latent representation, or the latent code, etc.. To train the encoder and the decoder, we cascade the decoder after the decoder, and train the cascaded neural network to reproduce outputs that are as close as the inputs.
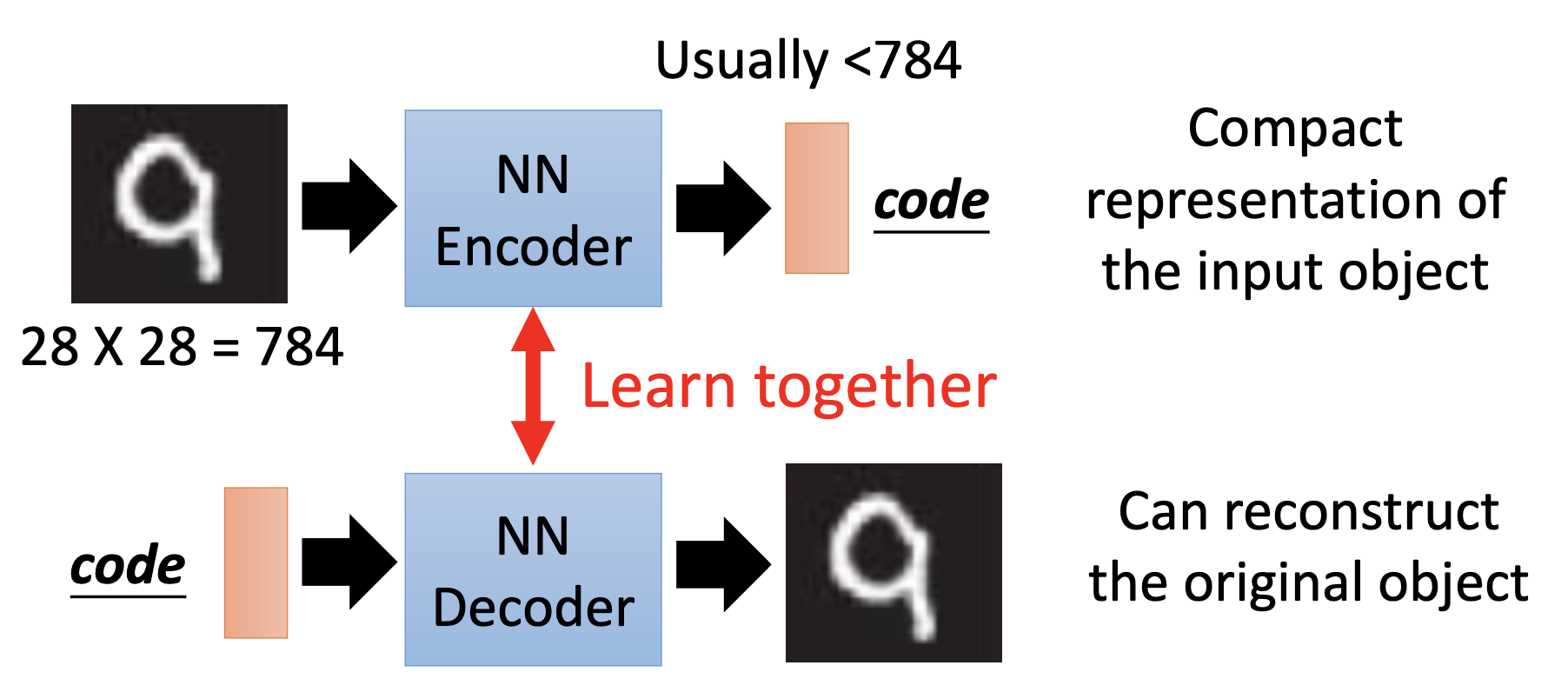
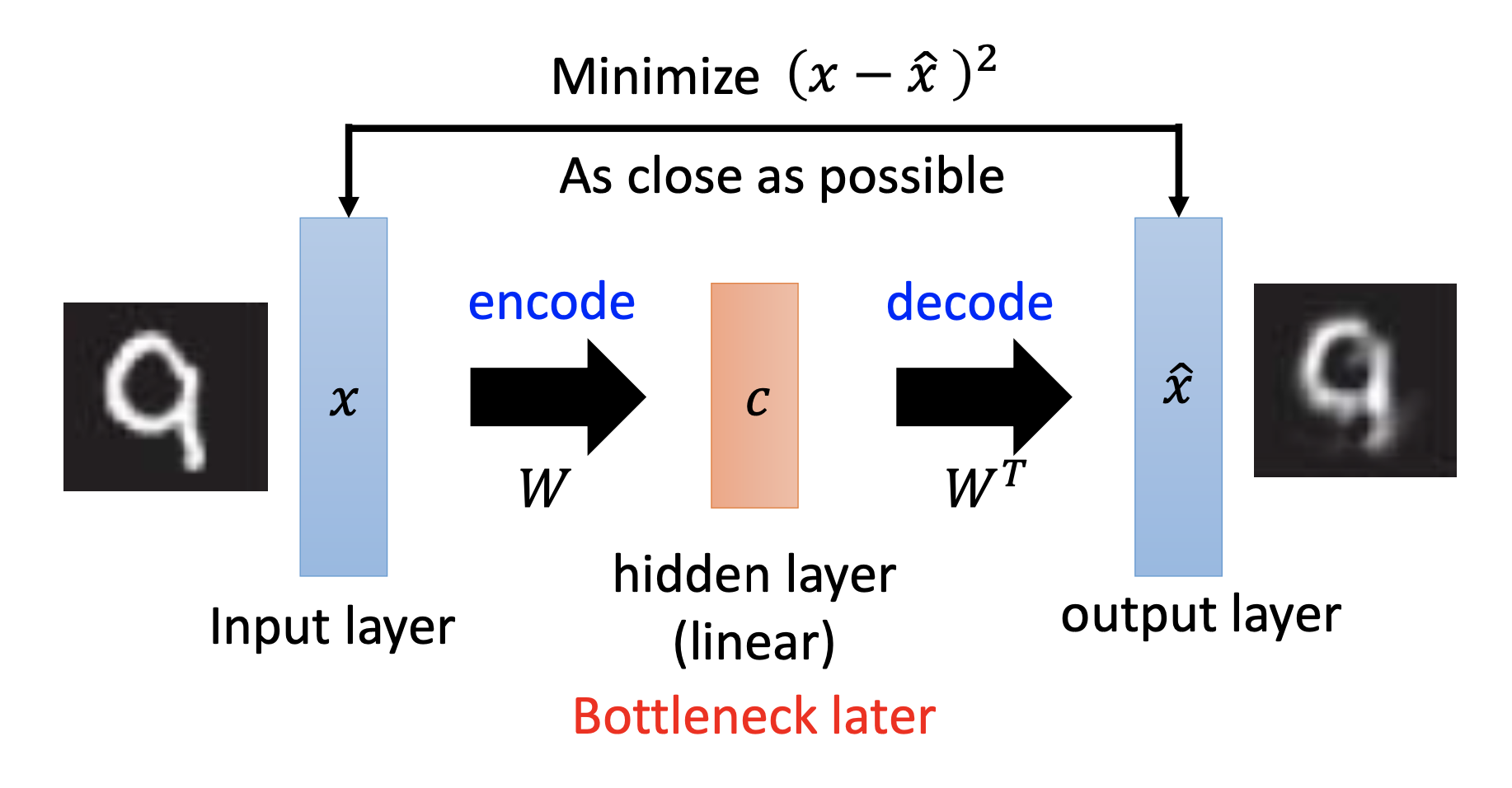
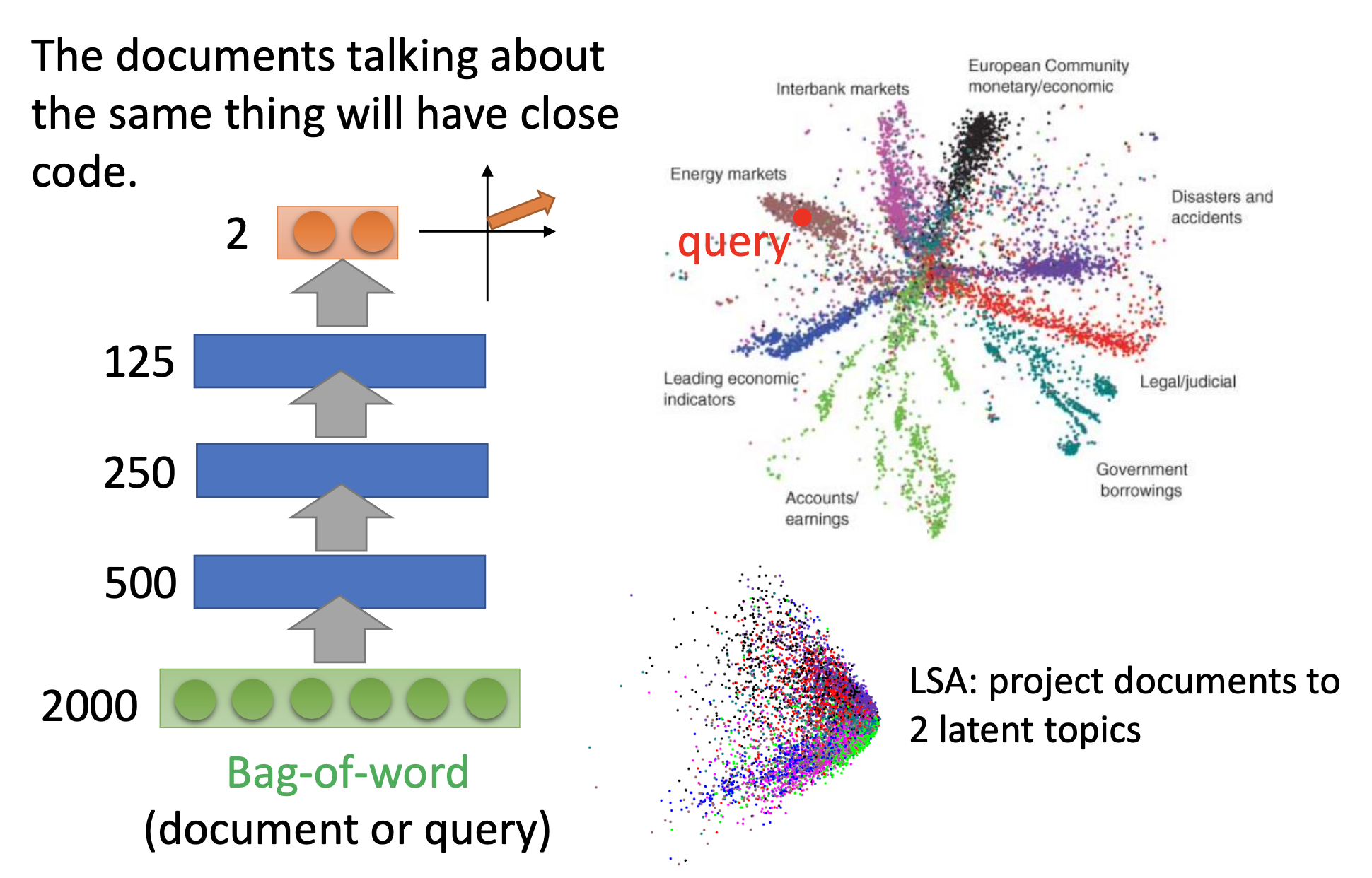
Comparing to principal component analysis, the auto-encoder’s training is like minimizing the reconstruction error in PCA. Combining the encoding and decoding parts of PCA as an auto-encoder, we can see the code as the output of the hidden layer. For dimension reduction, normally the code has the lowerest dimensionality in the whole auto-encoder, so it’s also the bottleneck layer.
Besides, for supervised learning, we always lack of (labelled) data; for un-supervised learning, we never lack of (unlabelled) data. That’s also why the auto-encoders are powerful.
Deep Auto-Encoder
Of course, the auto-encoder can be deep, so it’s deep auto-encoder.
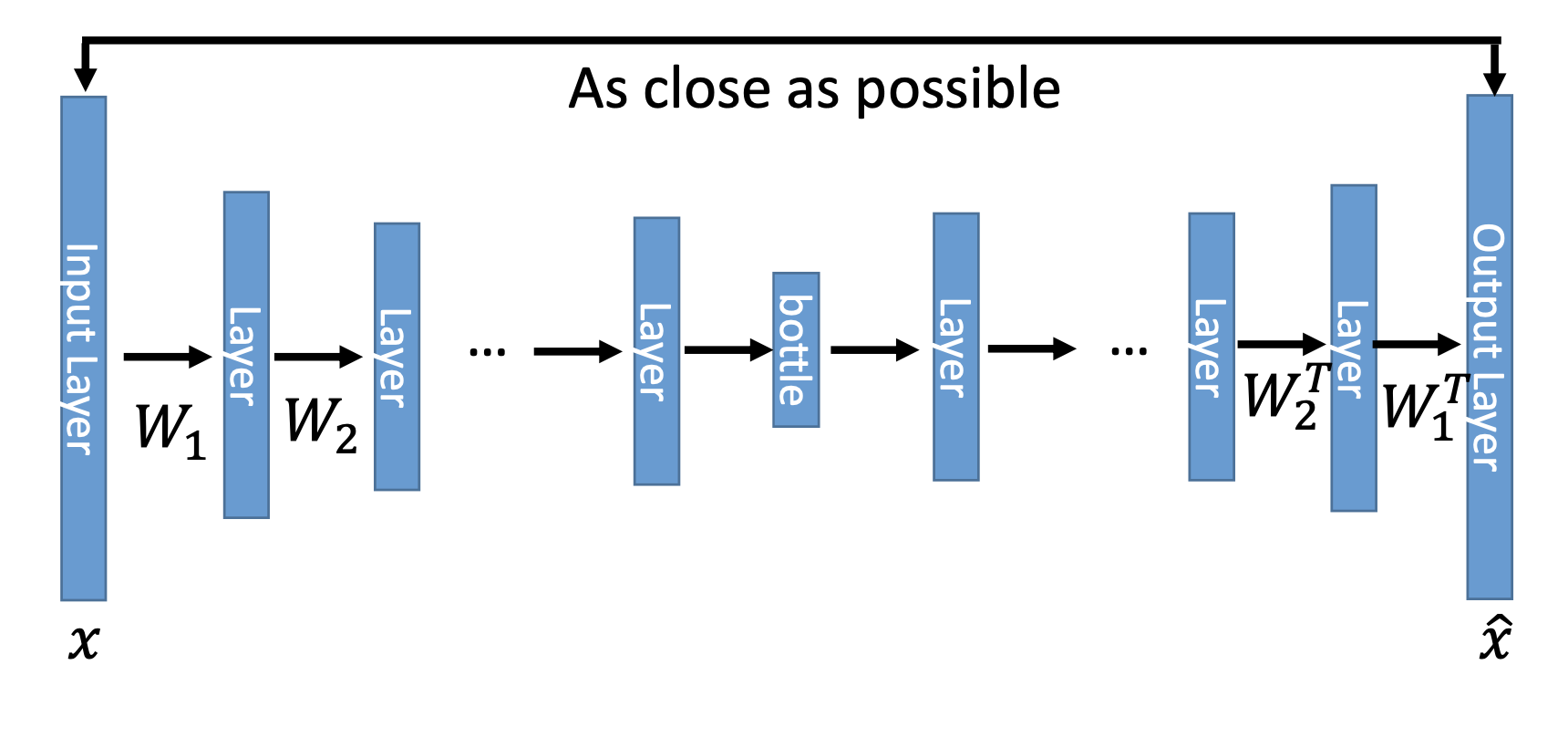
It’s not necessary to make the weights in the encoder and the decoder be symmetric. By applying the constrain of symmetry, we can reduce the number of parameters.
(My question: is the initialization by RBM still necessary for training auto-encoders today? No?)
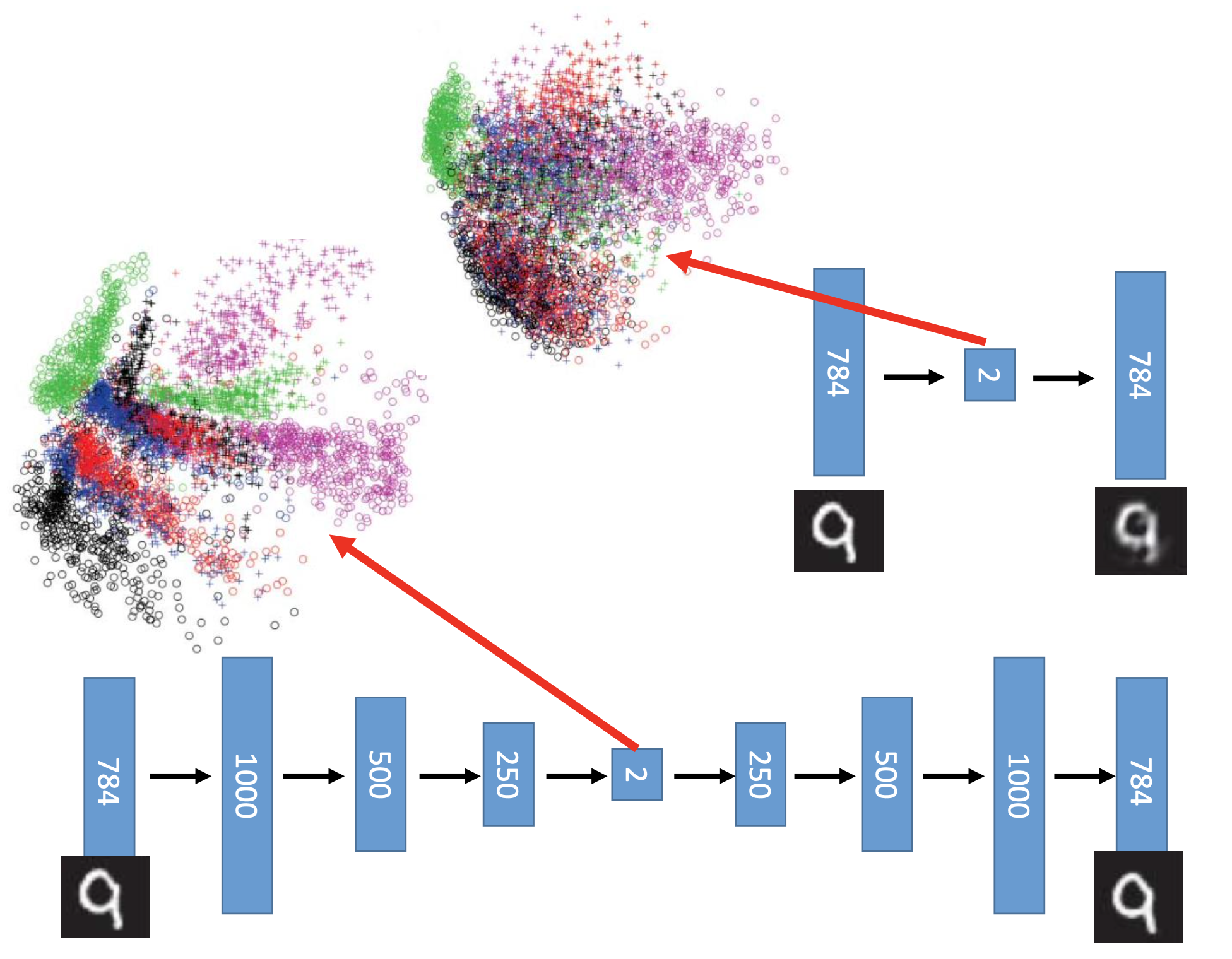
By making the auto-encoder deep, the generated code can seperate the different classes of the examples, although without supervised learning.
Text-Retrieval and Image Search
For text-retrieval, by the vector space model, we transform documents and also the query into vectors, and then we retrieve the documents by their similarities to the vector of the query.
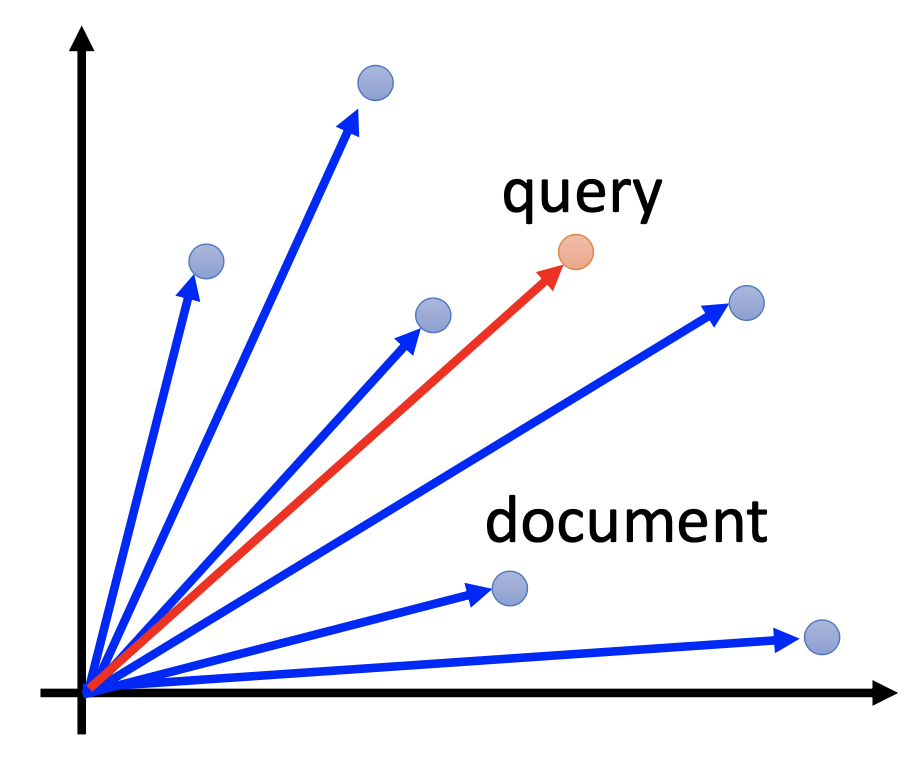
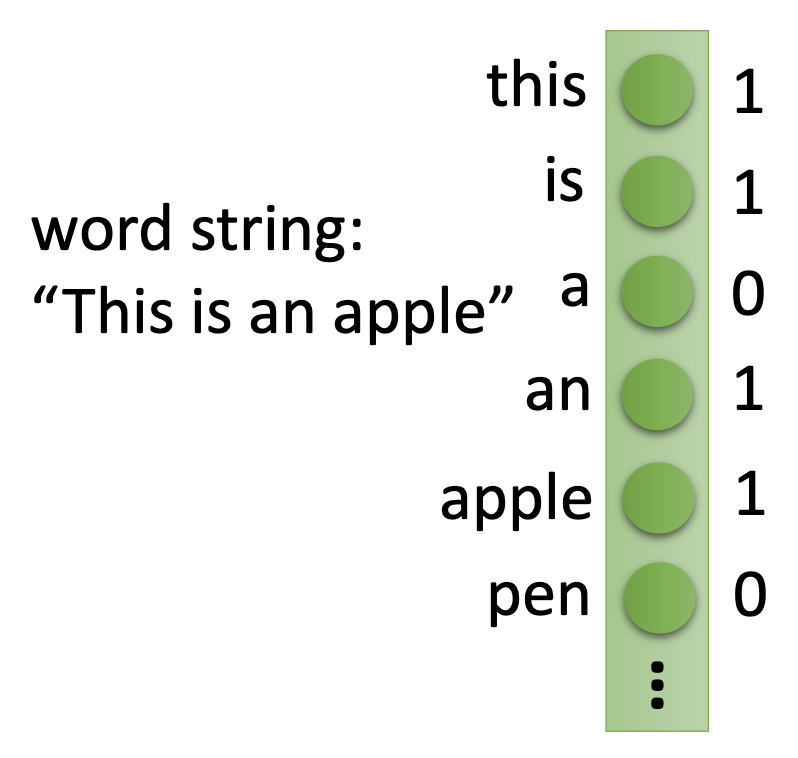
However, by only the bag-of-word model, the semantics are not considered.
If we further train an auto-encoder by the bag-of-word vectors of the documents, we can get good reslults for text-retrieval.
Similarly, for image search, if we perform the search directly by the vector of the pixels, we cannot find images with objects that are semantically similar. If we use the code of auto-encoders to perform the search, we can have better results.
Auto-Encoder for CNN
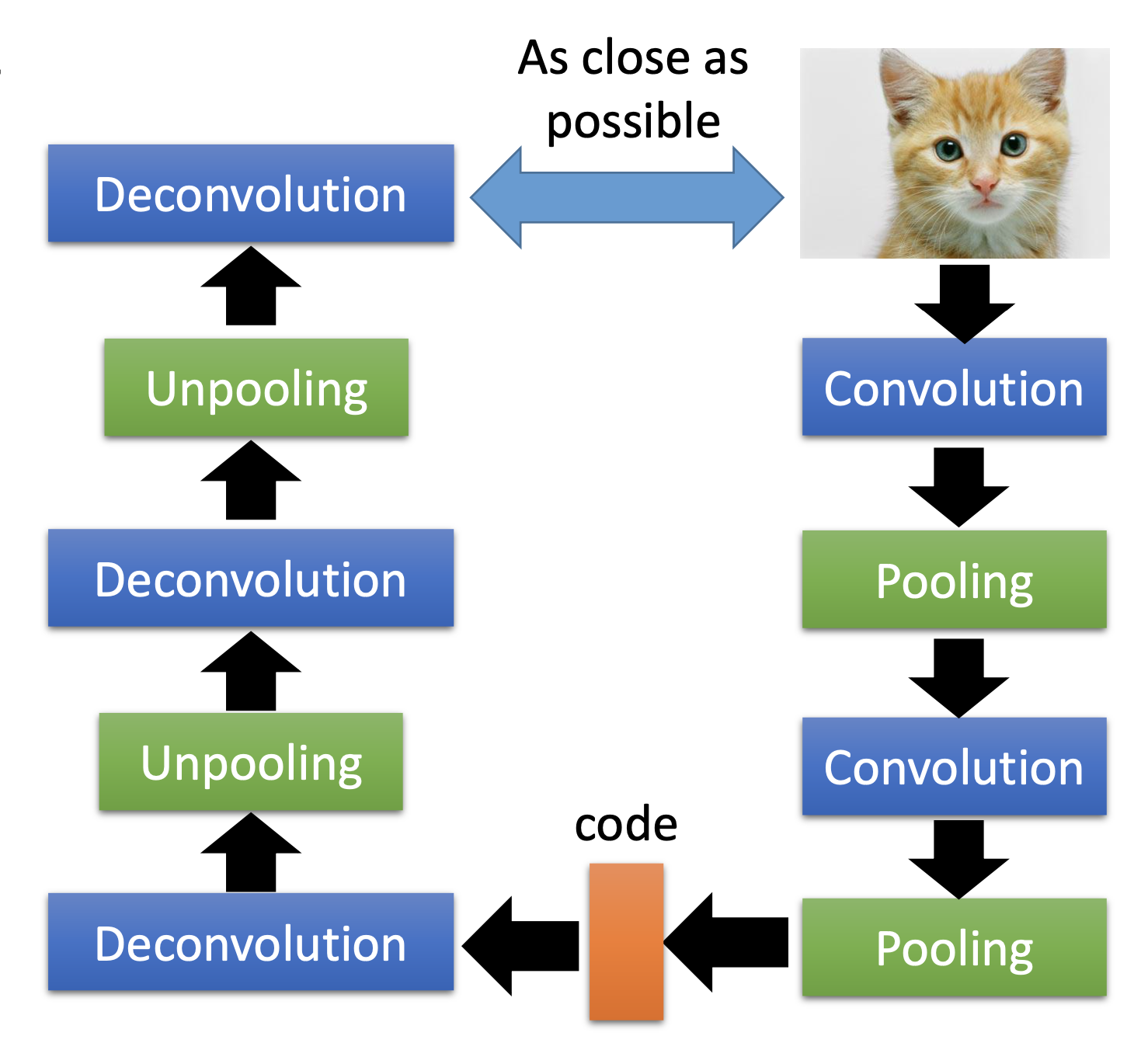
Unpooling
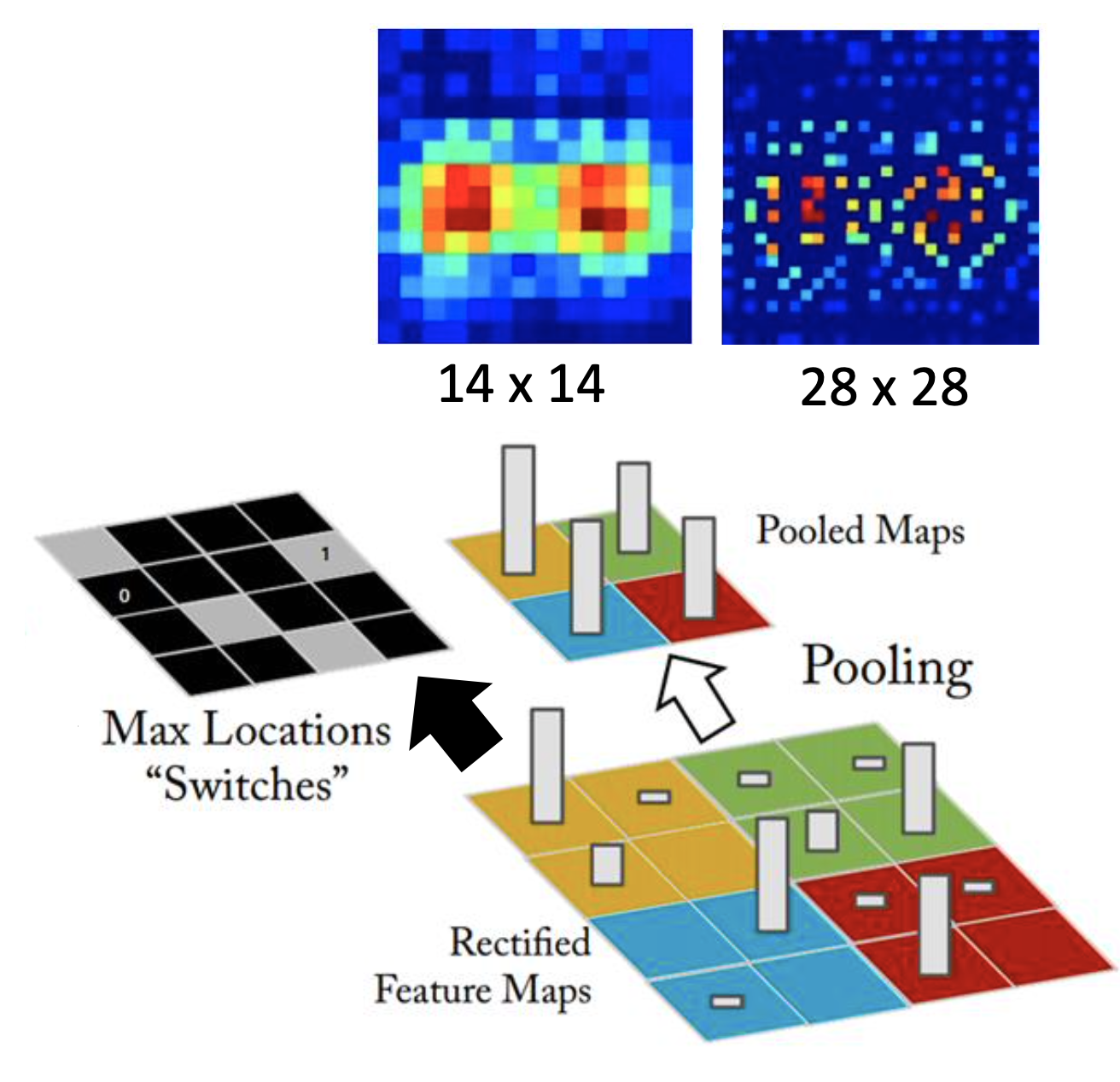
For unpooling, i.e. reverse the pooling, considering max pooling for example here, we perform the steps:
- Keep the max location maps at the pooling layers in the encoder.
- At the unpooling layer in the decoder, copy the pre-layer values to the recorded locations of the max location maps and set the values of all the other locations as 0.
Or as an alternitive, we can simply repeat the values to the enlarged map at the unpooling layers, like in Keras.
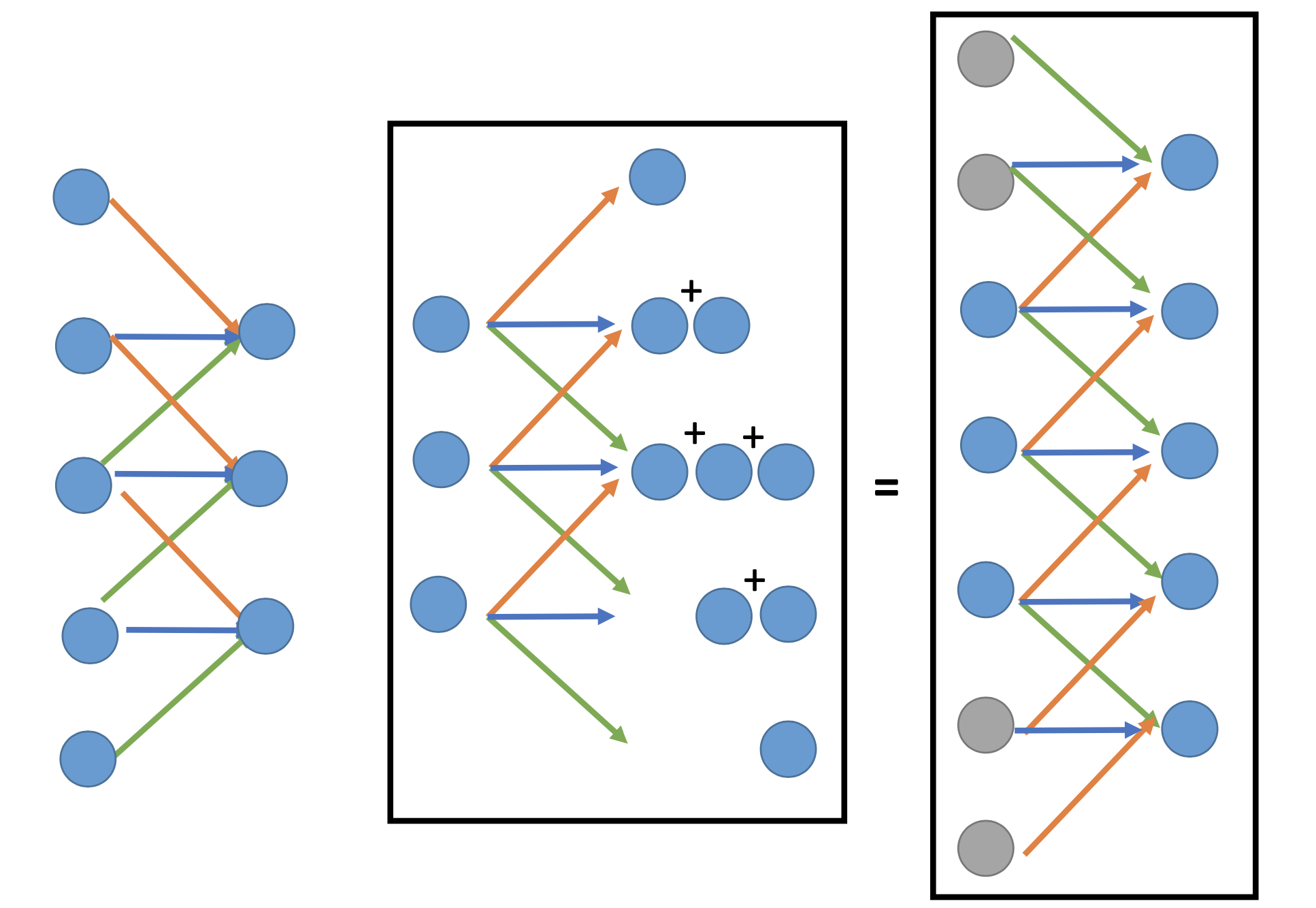
Deconvolution
Deconvolution is actually convolution with padding on the pre-layer of the deconcolution layer and reverse the index of the filter matrix at every dimension.
Use Auto-Encoder to Pre-Train DNN
To improve the training of deep neural networs, we can use auto-encoder for pre-training. First, we build anduse auto-encoders to train the hidden layers layer-by-layer. When training a hidden layer, we should fix the weights of all the other layers they we’ve already build. After pre-training all the hidden layers, we then train the whole network normally, i.e. the fine-tune.
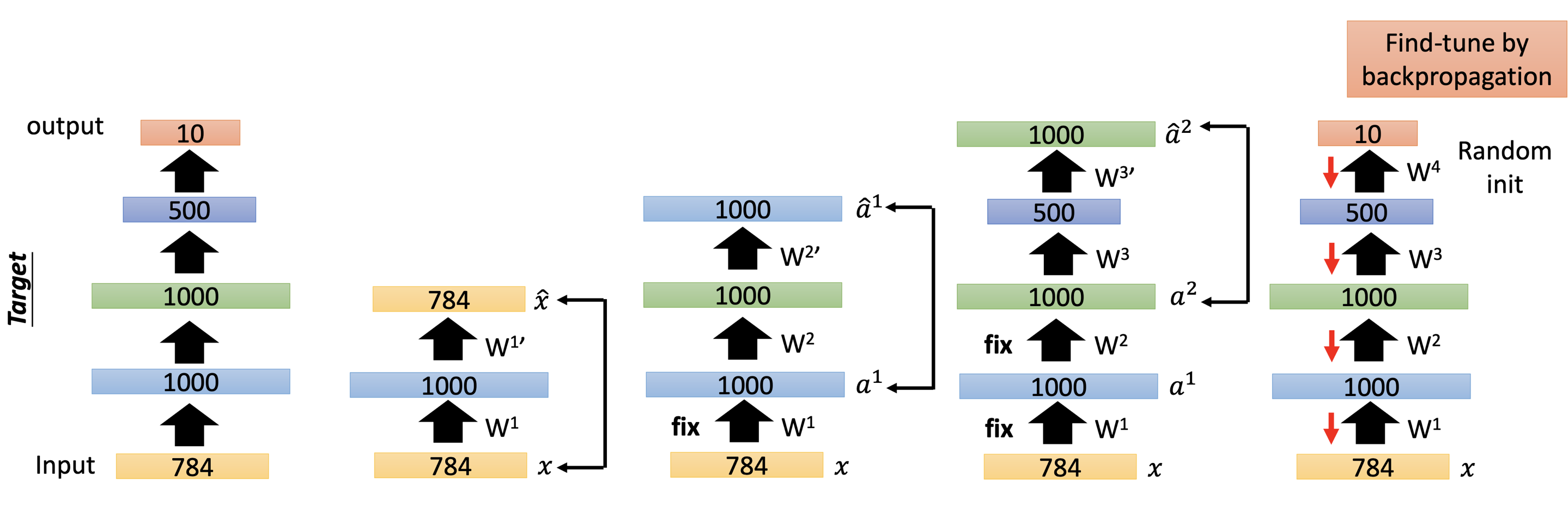
Today, ususally we don’t need pre-training. In the case that we have many unlabelled data, pre-training can still be helpful.
Beware that if the size of the layer that we are performing pre-training is larger that the size of its input, the training may be ineffective, i.e. it must learn to be something like identity matrix. In such cases, we can apply some strong regularization. e.g. L1 regularization, to ensure that the trained weights are going to be sparse.
More
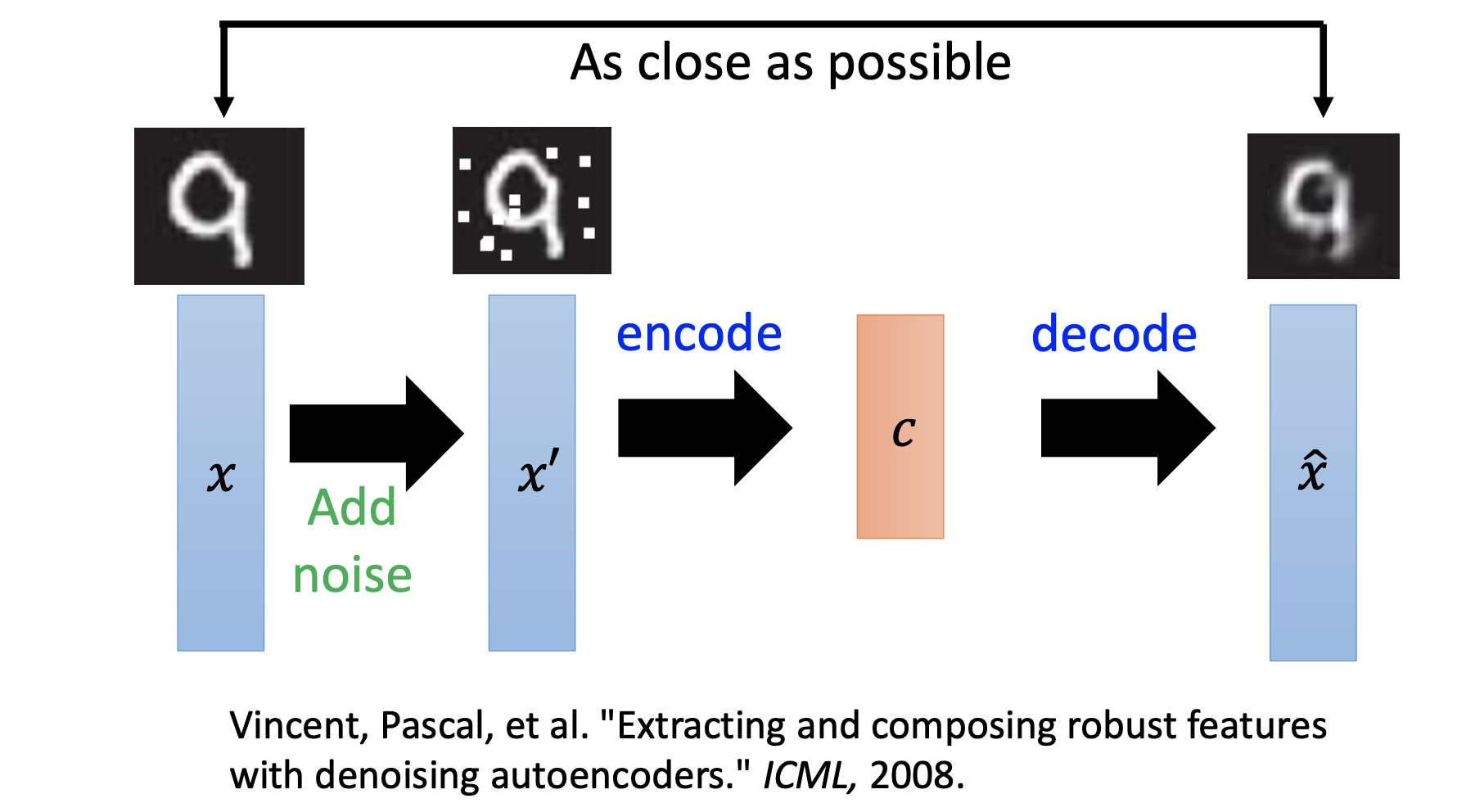
De-Noise Auto-Encoder
Add noise on the inputs, while use the original clean input as outputs for training the auto-encoder.
Constrictive Auto-Encoder
Let the code be insensitive to purterbations to the inputs
Ref: Rifai, Salah, et al. “Contractive auto-encoders: Explicit invariance during feature extraction.“ Proceedings of the 28th International Conference on Machine Learning (ICML-11). 2011.
Graph Co-Models
They are not neural networks!
Restrictive Boltzmann Machine: can be used for dimension redunction.
Or also, Deep Belief Network.
Please the references in the slides.