Notes for Prof. Hung-Yi Lee's ML Lecture 14: Word Embedding
Approaches to Represent Words
1-of-N Encoding
The total number of dimensions is the total number of words. The only 1 dimension with value 1 represent the corresponding word. By such approach, every word is independent and we can’t find the relationship between words.

Word class
Clustering the words. Since the relationships between the words are complex, so such clustering still lose many information.
Word Embedding
Performing dimension reduction to project 1-of-N encoding to high dimensional word vectors (whose dimensions are lower than the original 1-of-N encoding).
Generating word vectors is unsupervised. We use 1-of-N encoded words as input to generate their word embedding vectors, and the training data is a lot of text. Here we only have input data.
Generating the Word Vectors
We assume that a word can be understood by its context. Machine learns the meaning of words from reading a lot of documents without supervision.
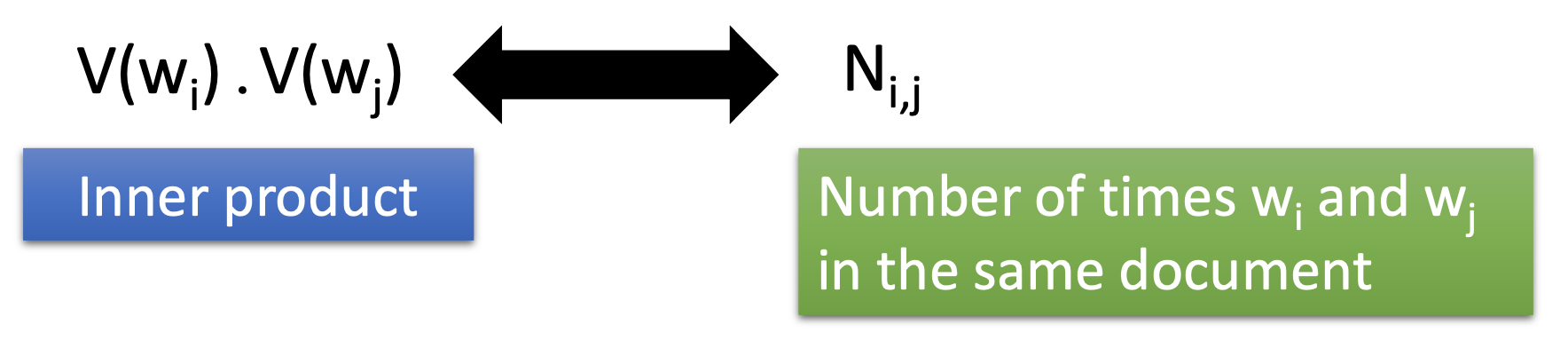
Count Based
If two words $w_i$ and $w_j$ frequently co-occur, $V(w_i)$ and $V(w_j)$ would be close to each other. e.g. Glove Vector. Such approach is similar to LSA or matrix factorization.
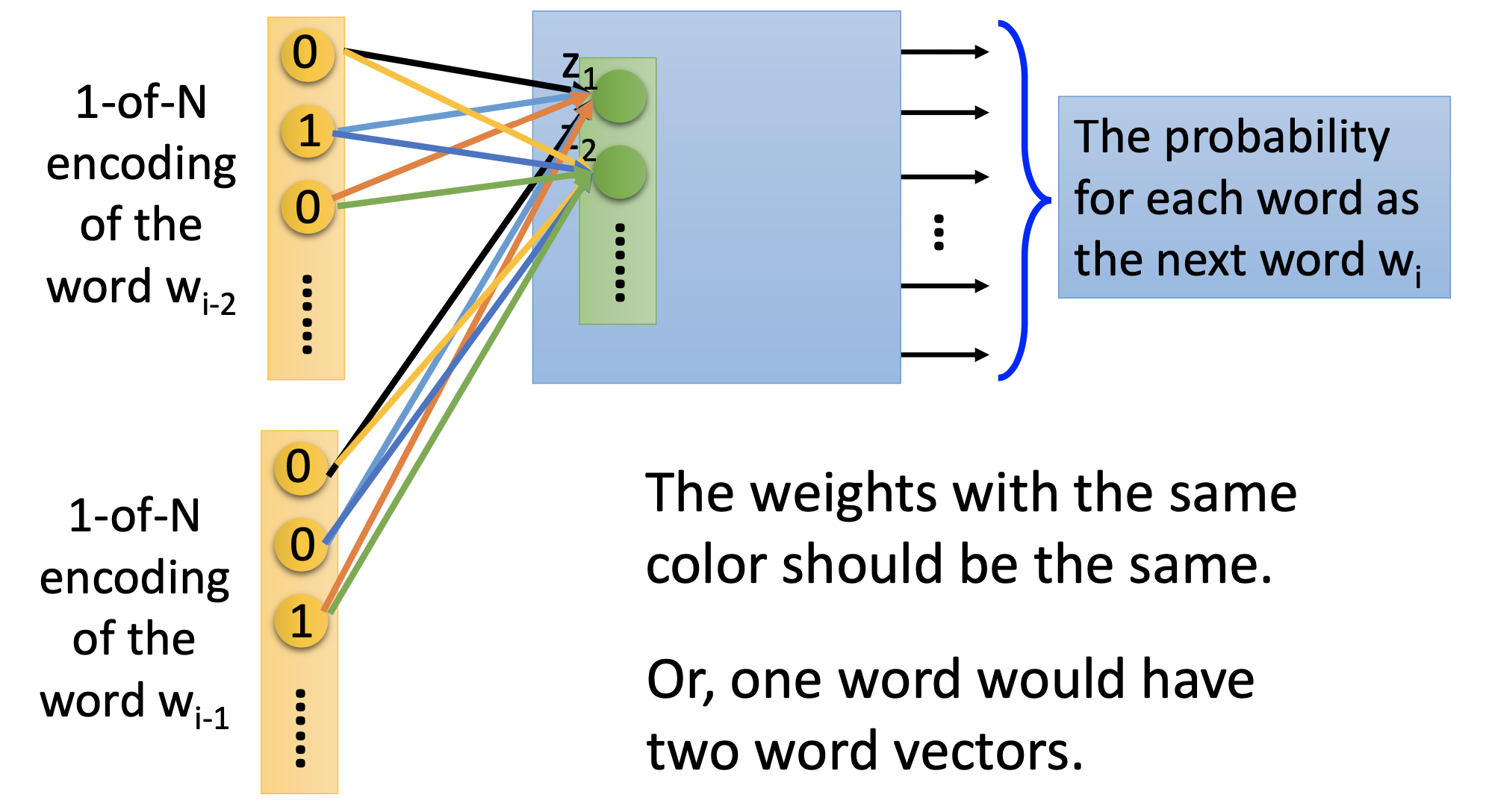
Preduction Based
Use some nearby words as input to produce the probability distribution of words at a position. After training, take the input at the 1st hidden layer as the word vector for the input word, i.e. the $z$ in the figure.
We can use the previous n words to predict a word,
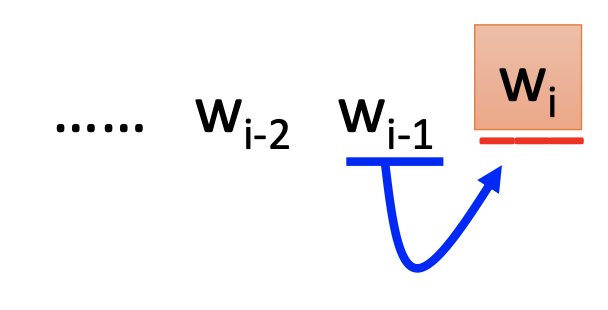
predicting the word given its context, i.e. use some previous and later words to predict a word, as the continuous bag of word (CBOW) model,

or predicting the context given a word as the skip-gram model.

Semantic Meanings of the Vectors
As high dimensional vectors, word embedding can handle the complex relationships between the words. Moreover, we can find semantic meanings in the arithmetic of the vectors, e.g.
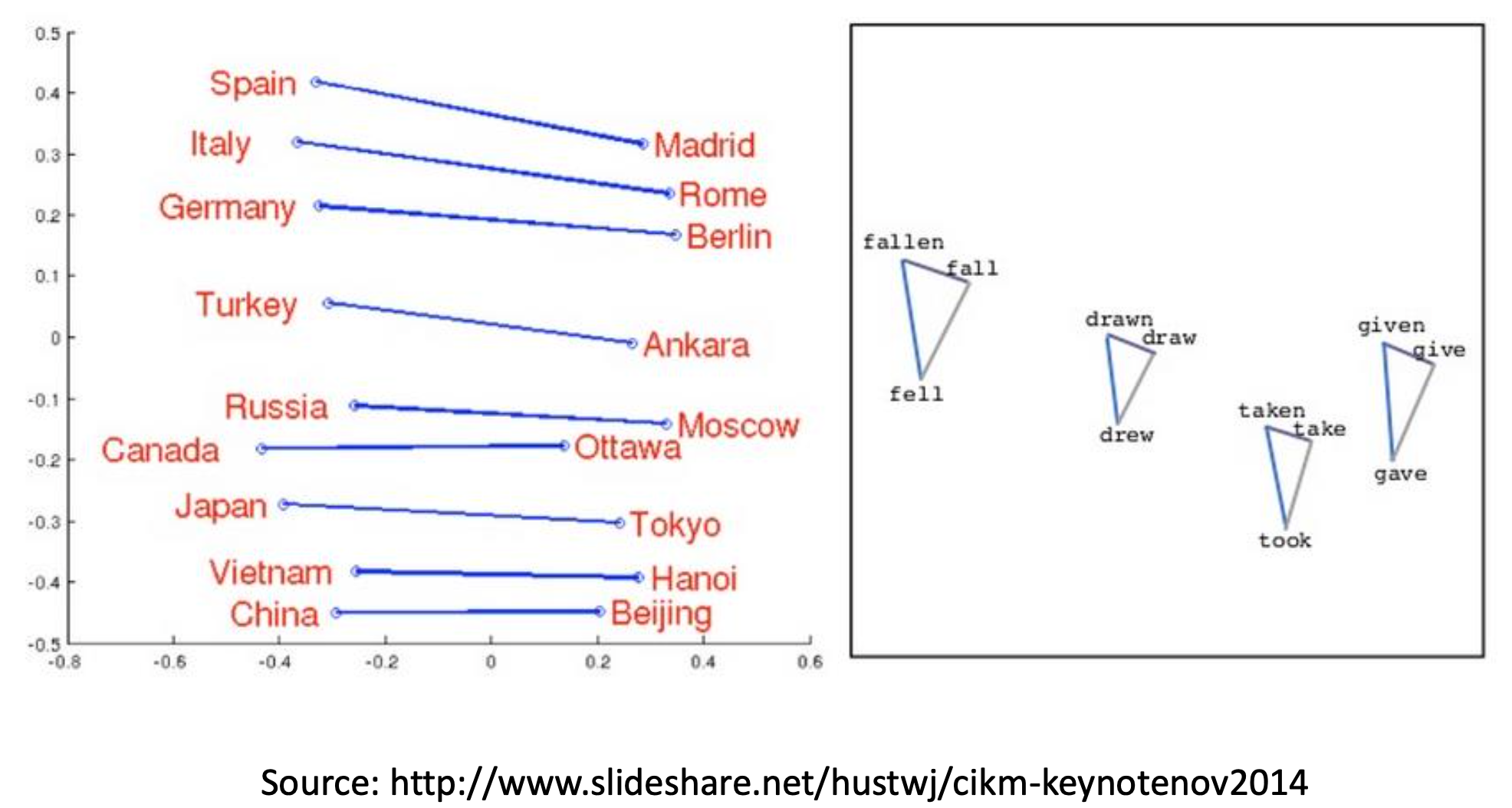
Discussion
Word embedding cannot be fulfilled by autoencoder. Reason: if we only have the 1-of-N encoded words as input and output, then the autoencoder can’t find any meaningful representations.
The neural network for generating the word vector has only 1 hidden layer, it’s not deep. By Tomas Mikalov, who proposed the word vector, the reasons are:
- There are many important tricks.
- The earlier works can’t complete the training of the NN due to lack of computing power.
- He want to show that such task can be fulfilled by non-deep neural networks.
(My conjecture) If the 1st hidden layer don’t sum the word vectors as 1 vector but keep the word vectors independently for processing of the later layers, would it better handles the sequential relationships of the words?
Multi-Lingual / Multi-Domain Embedding
We can make embedding for difference sources first, and then train a function to transform vectors from one source to tje vectors from another. Finally, we can use the result to perform translation between languages or mapping images to words. By such approaches, we can even handle data of classees that we’ve never had.
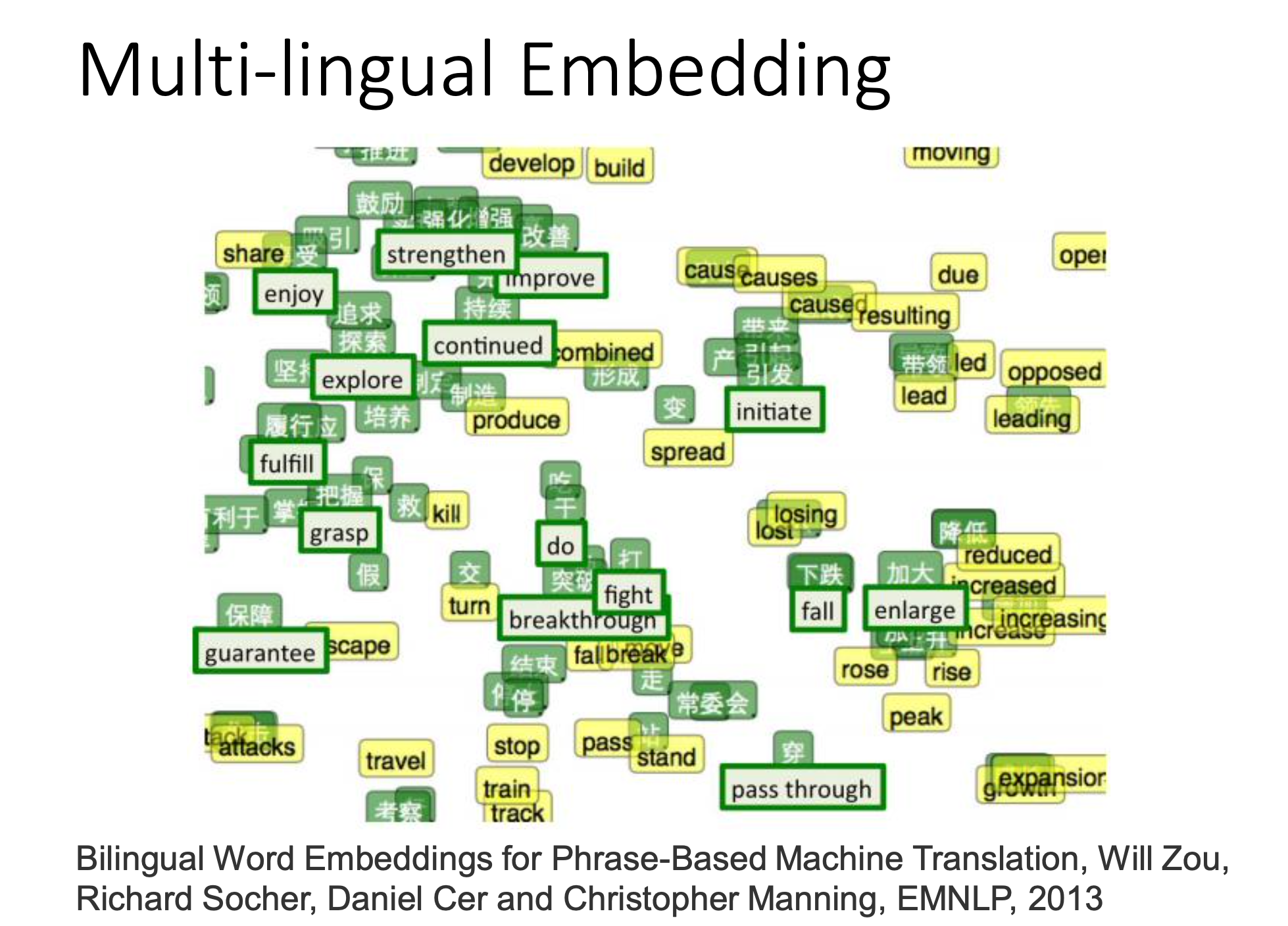
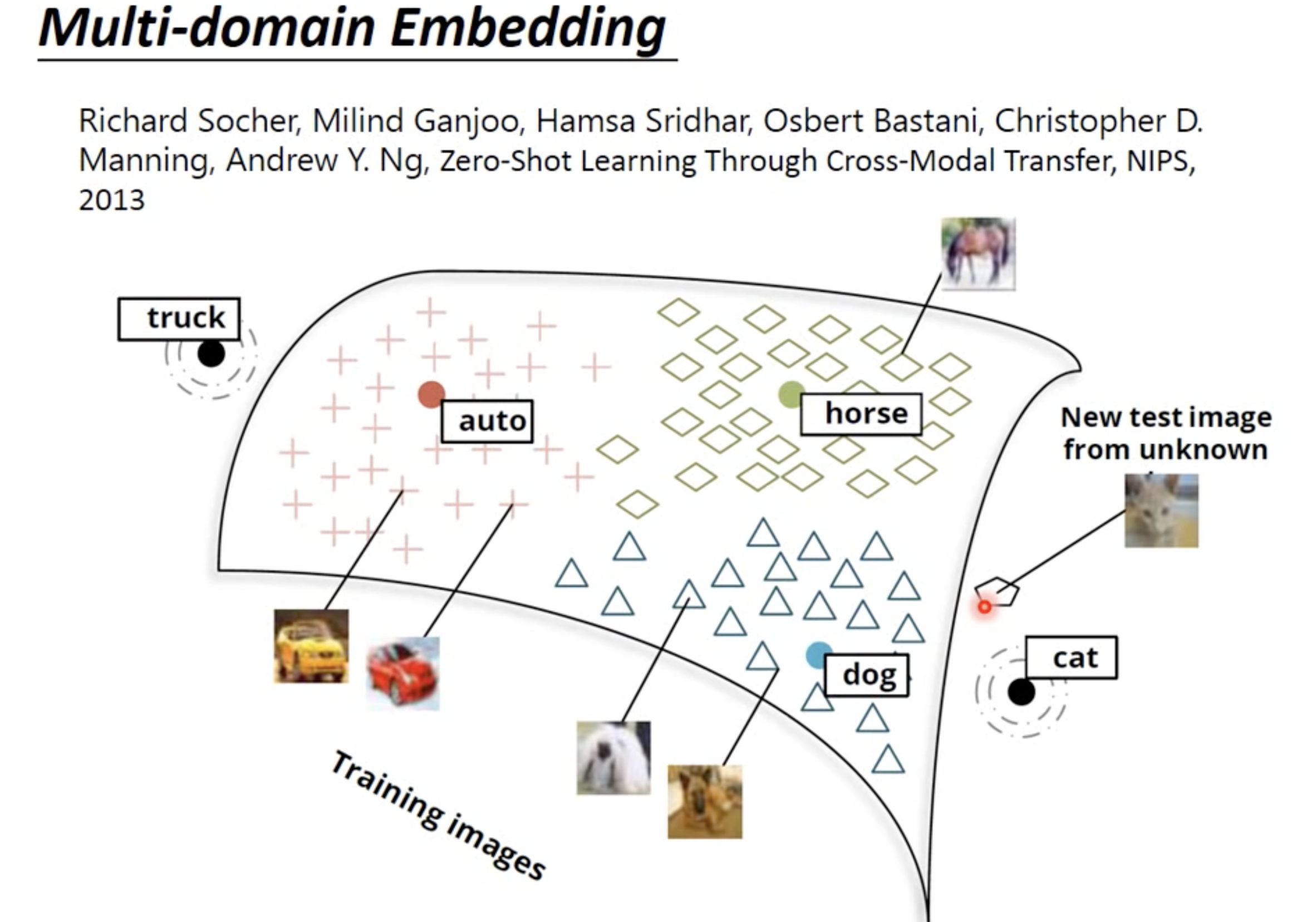
Document Embedding
By document embedding, we transform word sequences with different lengths to vectors with the same length, while the vectors represent the meaning of the word sequences. For example, the bag-of-world approach
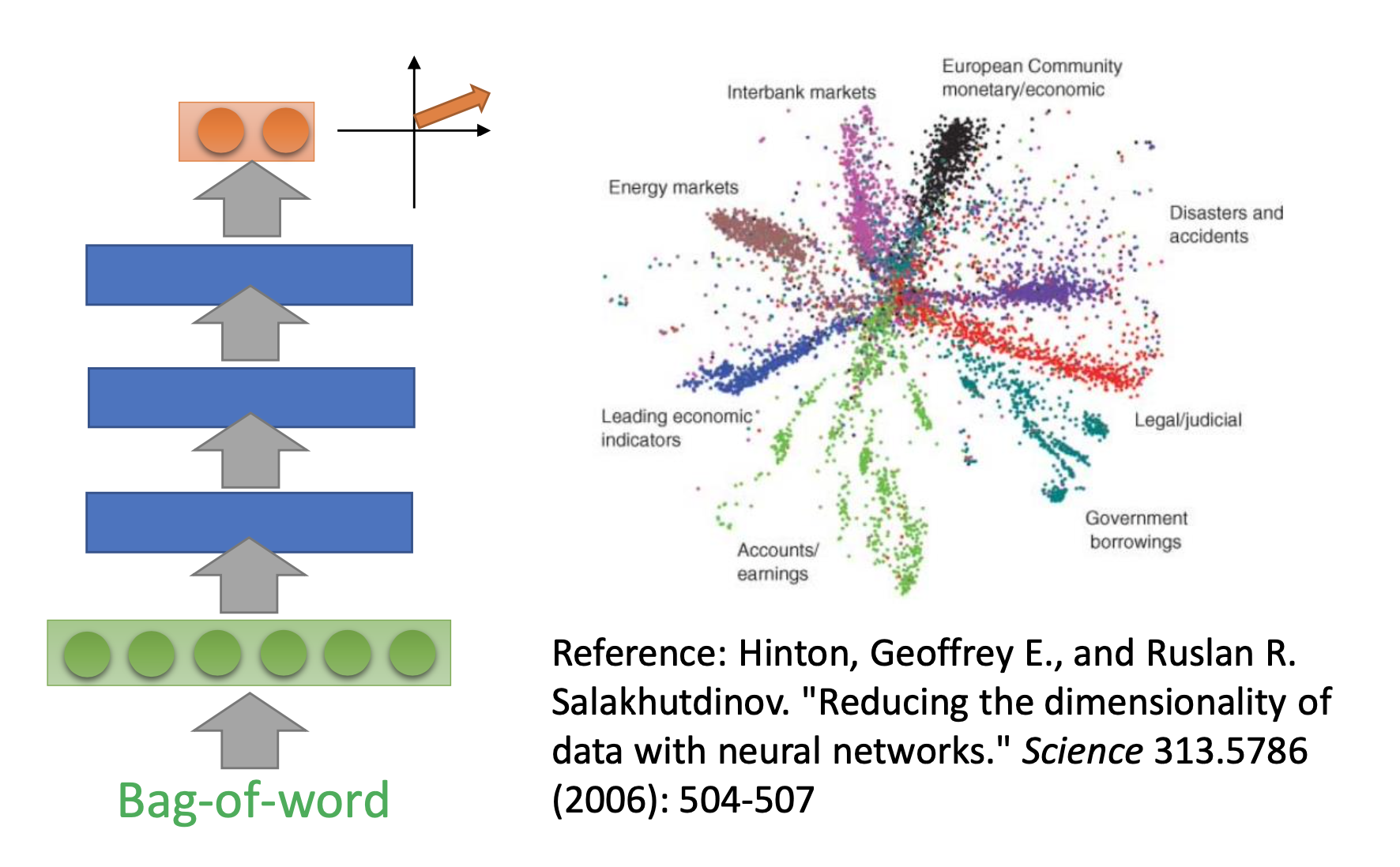
while in the bag-of-world approach, the order of the words is not considered, and the meaning of sentences can be completely different by different order. There are more approaches:

paragraph vector, seq2seq, skip through are unsupervised, and the others have some usage of labelled data.
References
Youtube ML Lecture 14: Unsupervised Learning - Word Embedding