Notes for Prof. Hung-Yi Lee's ML Lecture 11: Why Deep?
Having the same total number of parameters, the deep, i.e. thin and tail, neural networks, performs better than the fat abd short networks. The reason is that deep neural networks benefits from modularization, so they use the data and the parameters more efficiecntly.
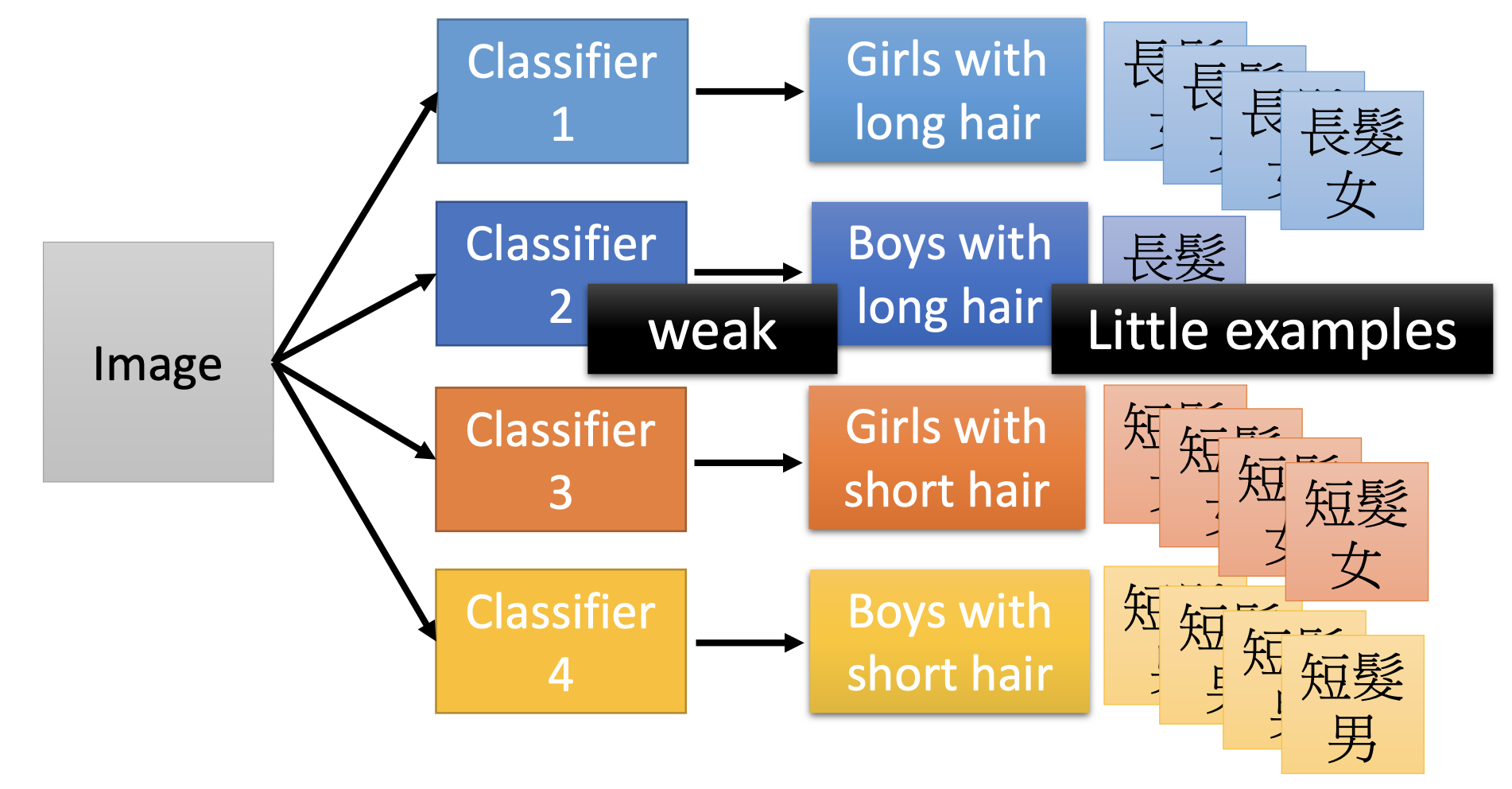
The concept of modularization here is that, using a deep neural network is actually decmoposing the problem to a hierarchy of functions and sub-functions by the deep layers, and the sub-functions, i.e. the neurons at the layers near the input end, can use almost the whole data set to learn their functions. In contrast, when training a fat and short neural network, most neurons, especially those near the output end, only be trained when they significantly contribute to the outputs, so most neurons are only trained by only a small portion of the training data.
The Deep Neural Networks
It has actually 2 layers.
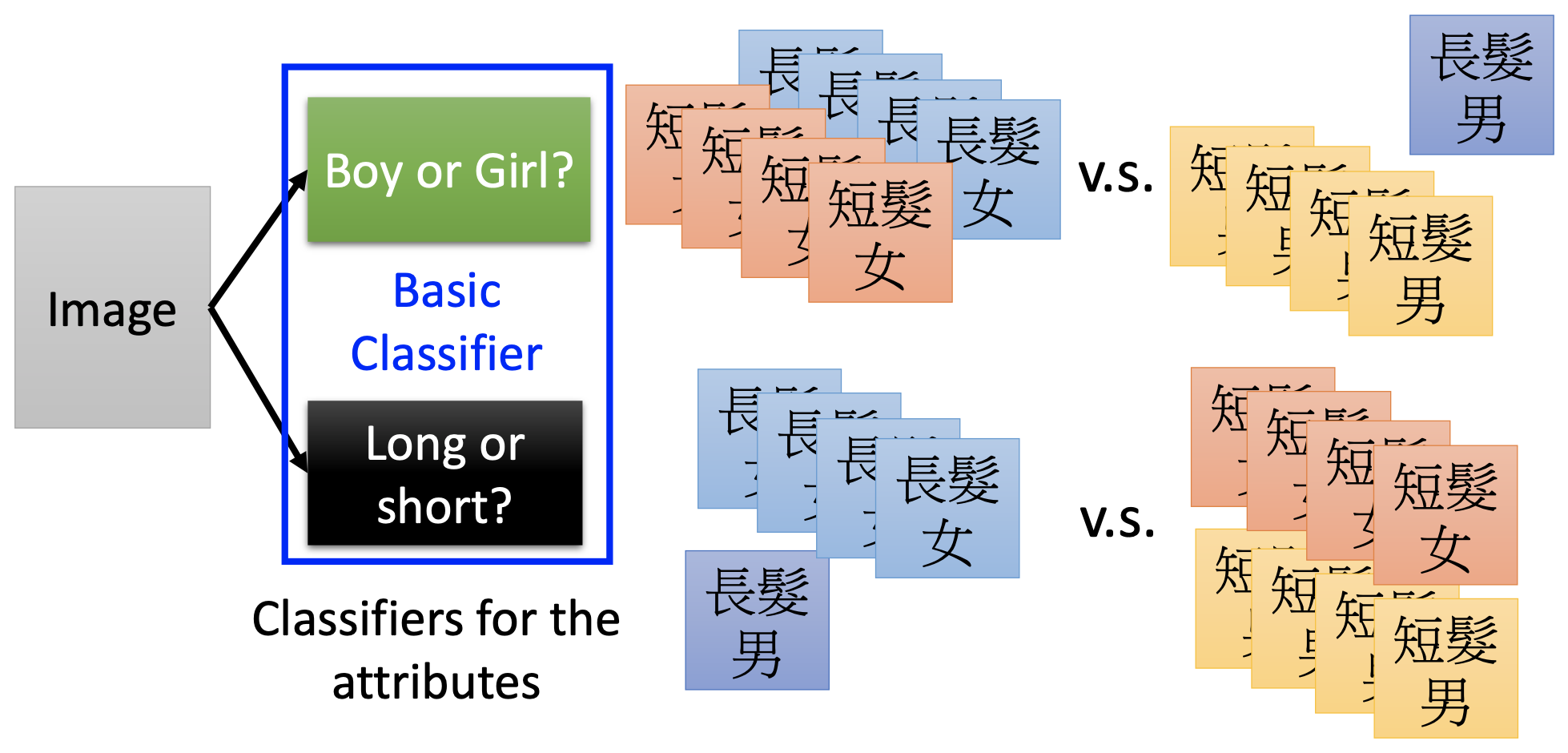
The Fat Neural Networks
It has only 1 layer.
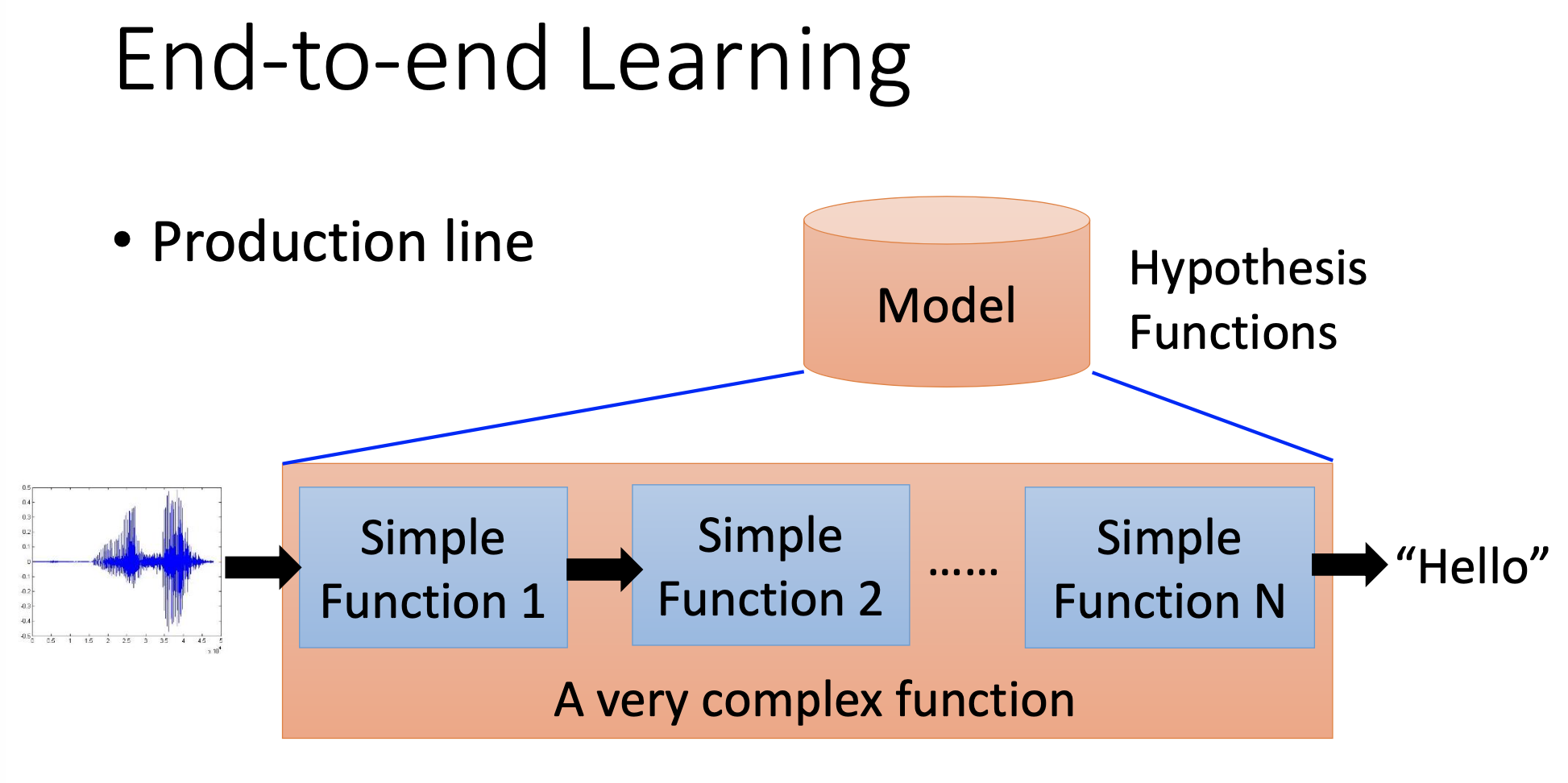
Deep learning can also perform end-to-end learning, i.e. let the deep neural networks learn from the inputs and outpus directly without making a series of processing functions by human design. Actually the trained deep neural networks can automatically resemble the series of processing functions designed by human.
By the effect of modularization, the deep neural networks actually use less parameters and need less training data. Therefore, the comment “deep learning simply take advantage of the high number of parameters to realize overfitting, it’s just a kind of brute force solution based on computing power and big data” is incorrect, because deep learning actually need less parameters and less data. The comment “deep learning is just neural networks + big data” is partially incorrect. The reason of incorrectness is like above. The correct part is that some tasks are just too complex that they do need big data, even deep learning is already very efficient for data.