Notes for Prof. Hung-Yi Lee's ML Lecture 6: Brief Introduction to Deep Learning
History of and Remarks on Deep Learning

The usage of the term “deep learning” actually changes with time. For example, at around 2006, “deep learning” refers to “the neural networks that uses Restricted Boltzmann Machine for initialization”, and “perceptron” indicated the ones without using RBM. while later people found that RBM actually has no effective benefits for NN, so it just draw people’s attention back to NN.
The multi-layer perceptron actually has no significant differences from the DNN today.
Why in 1986, people think that “more than 3 hidden layers are not helpful”? I guess due to tha lack of data and GPU.
Fully Connected Feedforward Network
The 1st step of ML, choosing the function set:
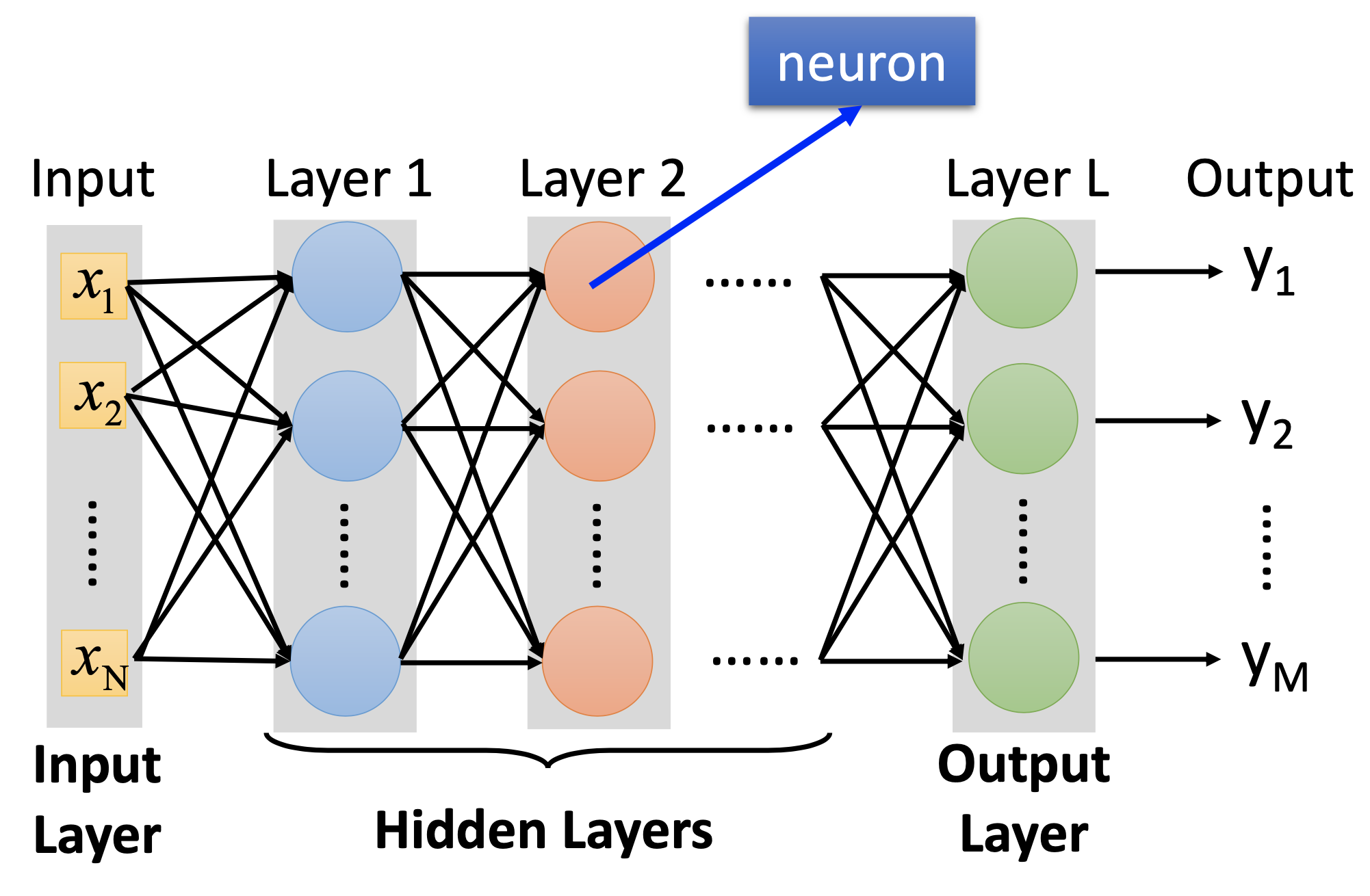
If we apply softmax on the output layer, then the NN becomes a multi-class classifier.
Also, we need to decide the network structure to let a good function in your function set.
The 2nd step of ML, goodness of functions:
If it’s for regression, then we can use RMS error; if it’s classification, then we use cross entropy.
The 3rd step of ML, find the best function:
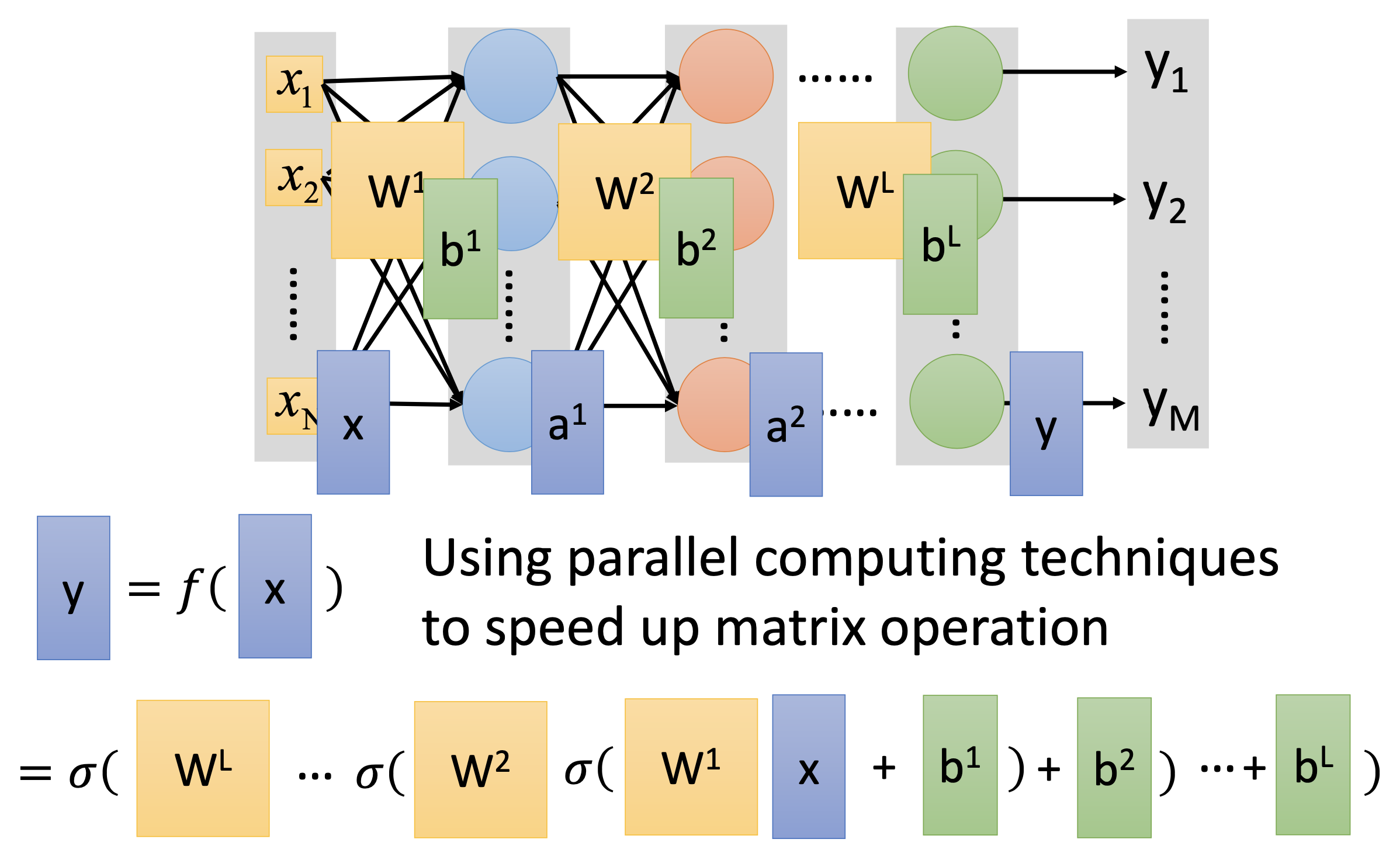
Use gradient descent to find the best weights $w$ and biases $b$. To effectively calculate the derivatives, we use backpropagation.
Discussions
Special structure of extremely deep NNs
The 152 layers deep Residual net has special structures and is not fully connected feedforward, or it’ll be untrainable.
Design of NN structure
When designing an NN, we can only rely on trial-and-error and intuition.
The hidden layers are actually feature extractors that replace the feature engineering. The shift from machine learning to deep learning is actually transforming the questions from feature engineering to neural network structure design.
The domains that people can find more structural and conceptual innovations actually feel less improvement by the introduction of DL, e.g. NLP. Although now DL still dominate in NLP, but not so powerful like in computer vision of speech recognition.
We can also let the model automatically determine its structure, it’s Evolving Artificial Neural Network.
Deep is Better?
When the network is deeper, there are more parameters, i.e. larger function set, so it should be beter.
Universality Theorem
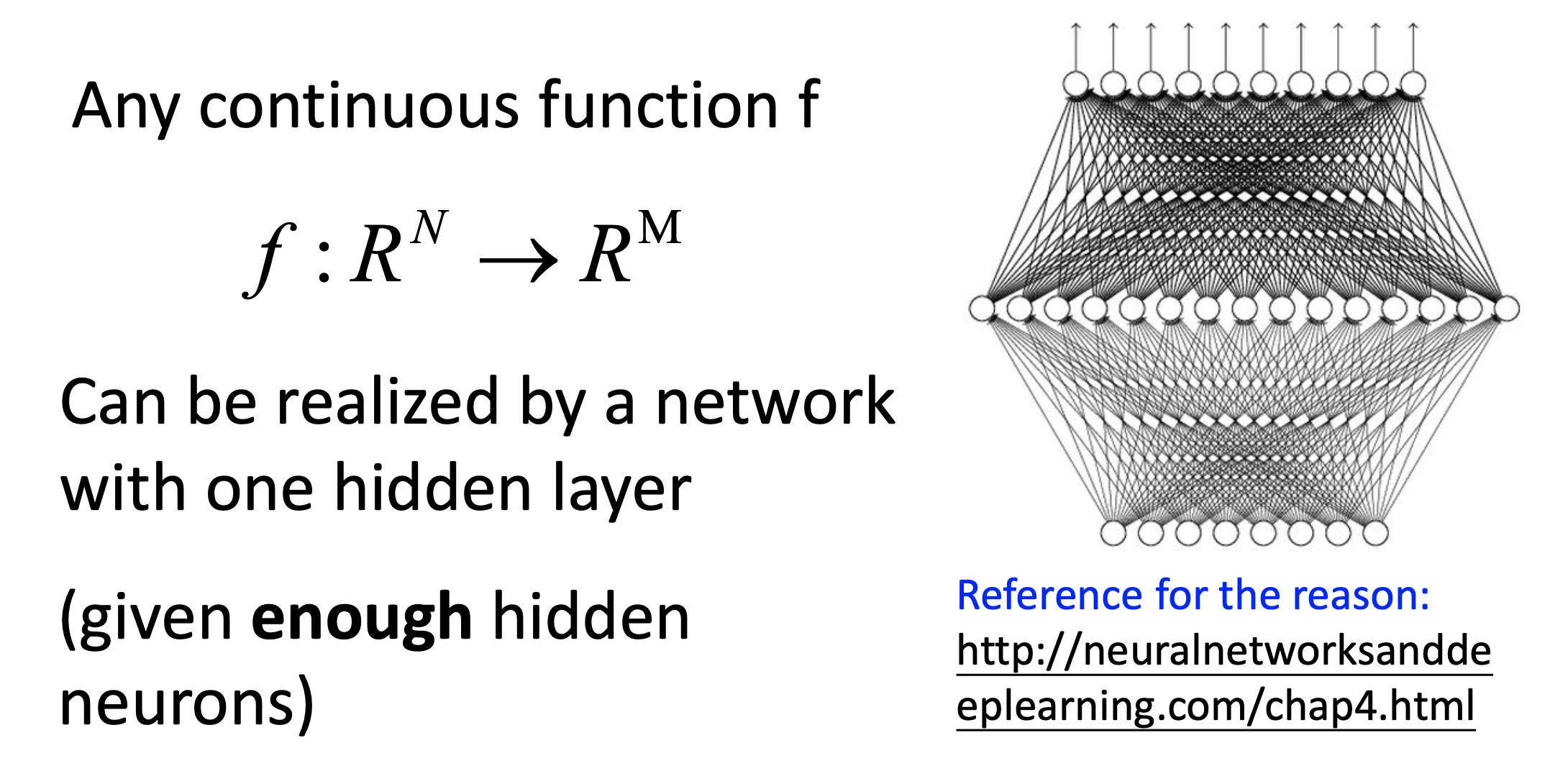
In the later lectures, we’ll see why we choose “deep” but not “fat” neural networks.